-
日期: 2024-06-03 | 來源: 智東西 | 有0人參與評論 | 字體: 小 中 大
5、在壹些未公開的實驗性特征上,比如在內部私有數據上訓練的古漢字清華竹簡,Llama3-V表現出與MiniCPM-Llama3-V 2.5高度相似的推理結果。這些訓練圖像是最近從出土文物中掃描並由面壁智能的團隊注釋的,尚未公開發布。
例如下圖中的幾個古漢字識別:
MiniCPM-Llama3-V 2.5中未公開的WebAgent功能上,在框選內容大小時,Llama3-V與之犯了相同的錯誤: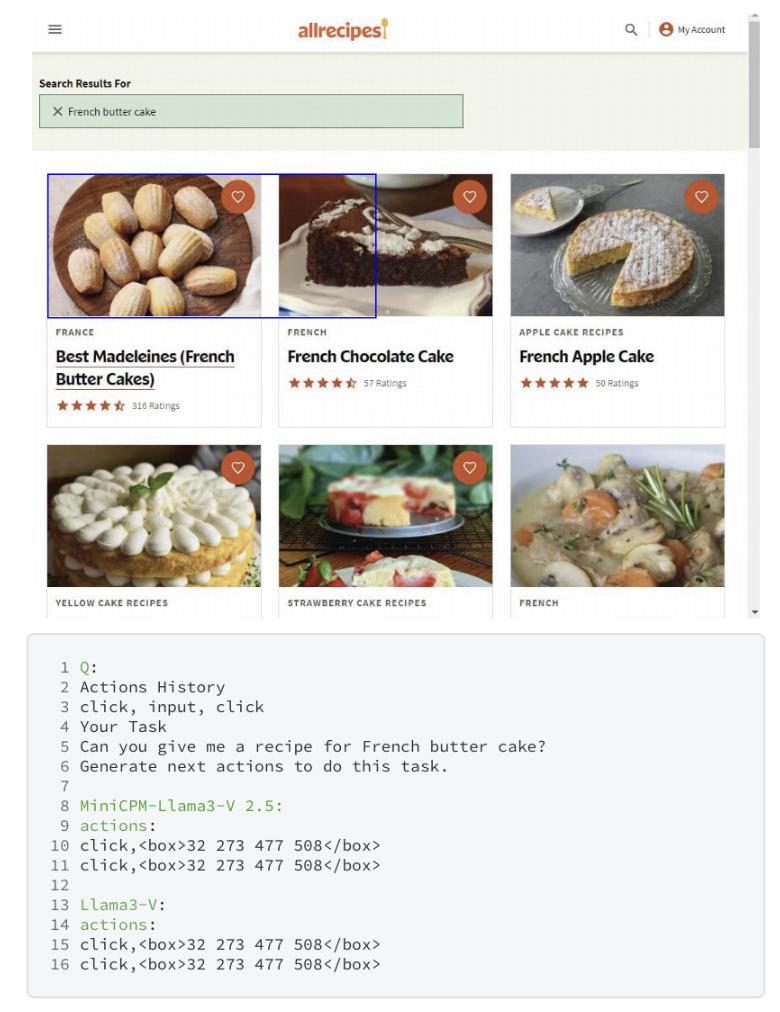
02.仨作者內訌,Aljadery全權負責寫代碼 ,但拿不出訓練代碼
昨天,Aksh Garg、Siddharth Sharma在外媒Medium上公開回應:“非常感謝在評論中指出(Llama3-V)與之前研究相似之處的人。我們意識到我們的架構與OpenBMB的‘MiniCPM-Llama3-V2.5:手機上的GPT-4V級多模態大模型’非常相似,他們在實現方面領先於我們。為了尊重作者,我們刪除了原始模型。”Aljadery沒有出現在聲明中。
▲Aksh Garg、Siddharth Sharma的回應聲明
Mustafa曾在南加州大學從事深度學習研究,並在麻省理工學院從事並行計算研究,擁有南加州大學計算機科學學士學位和計算神經科學理學士學位,目前其沒有在公司任職。
Garg在社交平台X中發布的致歉聲明中提到,Mustafa全權負責編寫Llama3-V的代碼,他與Sharma因忙於全職工作並未參與代碼編寫。
在聽取了Mustafa描述的Idefics、SigLip等架構擴展創新、查看了最新論文後,他們贰人就在未被告知該項目與開源代碼關系的情況下,幫助Mustafa在外媒Medium和社交平台X對Llama3-V進行了宣傳推廣。
在昨天看到關於Llama3-V的抄襲指控後,Garg和Sharma就與Mustafa進行了原創性討論,並要求他提供訓練代碼,但目前未收到任何相關證據。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見