-
日期: 2025-01-31 | 來源: 傅裡葉的貓/基本常識 | 有0人參與評論 | 字體: 小 中 大
例如,能在筆記本電腦上運行的小型模型,其性能可與 GPT-3 相媲美,而 GPT-3 的訓練需要超級計算機,推理則需要多個 GPU。換句話說,算法的改進使得用更少的計算資源來訓練和推理具有相同能力的模型成為可能,這種模式反復出現。這次全世界之所以關注,是因為它來自中國的壹個實驗室。但小型模型性能提升並非新鮮事。
到目前為止,我們從這種模式中看到,人工智能實驗室為了獲得更高的智能水平,在絕對金額上的投入越來越多。據估計,算法的進步意味著每年實現相同能力所需的計算資源減少 4 倍。Anthropic 的首席執行官 Dario 認為,算法定價在朝著 GPT-3 質量發展,成本已下降 1200 倍。就推理而言,甚至可以實現 10 倍的改進。
在研究 GPT-4 的成本時,我們也看到了類似的成本下降趨勢,不過處於曲線的更早期階段。雖然隨著時間推移成本差異的縮小,不能像上面的圖表那樣通過保持能力不變來解釋。在這種情況下,我們看到算法改進和優化使成本降低了 10 倍,同時能力也有所提升。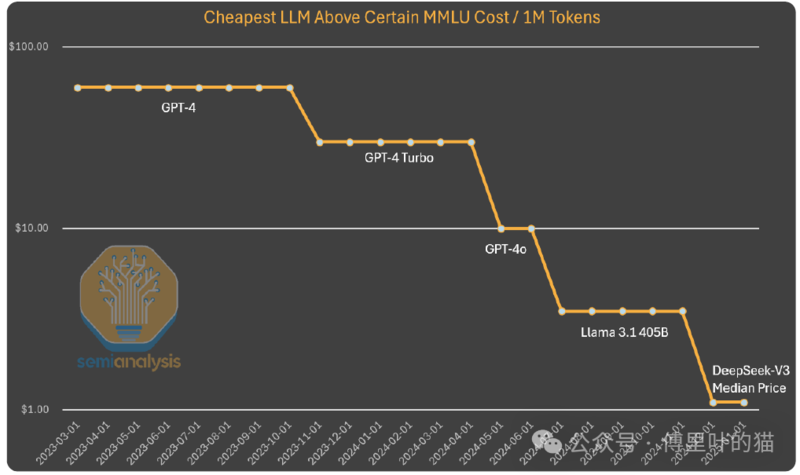
需要明確的是,深度求索的獨特之處在於他們率先達到了這樣的成本和能力水平。他們發布開放權重的做法也很獨特,不過之前 Mistral 和 Llama 模型也有過類似舉措。深度求索達到了這樣的成本水平,但到今年年底,如果成本再下降 5 倍,也不要感到驚訝。
另壹方面,R1 能夠取得與 o1 相當的結果,而 o1 直到 9 月才發布。深度求索是如何這麼快就追趕上的呢?
答案是,推理是壹種新范式,與之前的預訓練范式相比,它的迭代速度更快,且更容易實現較小計算量下的顯著提升,而之前的預訓練范式成本越來越高,且難以取得穩健的進展。如我們在報告中所述,之前的范式依賴於規模定律。
新范式通過在現有模型的訓練後階段,利用合成數據生成和強化學習來提升推理能力,能夠以更低的成本實現更快的進步。較低的進入門檻和易於優化的特點,使得深度求索能夠比往常更快地復制 o1 的方法。隨著參與者在這種新范式中找到更多擴展方法,我們預計實現相同能力所需的時間差距將會擴大。
需要注意的是,R1 的論文中並未提及所使用的計算資源。這並非偶然 —— 為訓練後的 R1 生成合成數據需要大量計算資源,更不用說強化學習了。我們並不否認 R1 是壹款非常優秀的模型,能如此迅速地在推理能力上追趕上令人欽佩。深度求索作為壹家中國公司,用更少的資源實現了追趕,這更是令人贊歎。
但 R1 提到的壹些基准測試也具有誤導性。將 R1 與 o1 進行比較很棘手,因為 R1 特別沒有提及那些自己不領先的基准測試。雖然 R1 在推理性能上與 o1 相當,但它並非在所有指標上都是明顯的贏家,在很多情況下甚至不如 o1。
我們還沒有提到 o3。o3 的能力明顯高於 R1 和 o1。事實上,OpenAI 最近公布了 o3 的結果,其基准測試成績直線上升。“深度學習遇到了瓶頸”,但卻是另壹種情況。
谷歌的推理模型與 R1 相當在人們為 R1 瘋狂炒作時,壹家市值 2.5 萬億美元的美國公司 —— 谷歌,提前壹個月發布了壹款推理模型 Gemini Flash 2.0 Thinking,且價格更低。這款模型可供使用,通過 API 調用時,即使其上下文長度更長,價格也比 R1 便宜得多。
在已公布的基准測試中,Flash 2.0 Thinking 的表現優於 R1,盡避基准測試並不能說明全部情況。谷歌只公布了 3 個基准測試結果,所以這只是壹個不完整的畫面。不過,我們認為谷歌的模型很可靠,在很多方面都能與 R1 抗衡,卻沒有得到任何炒作。這可能是因為谷歌的市場推廣策略平淡無奇,用戶體驗也不佳,但也可能是因為 R1 來自中國,令人感到意外。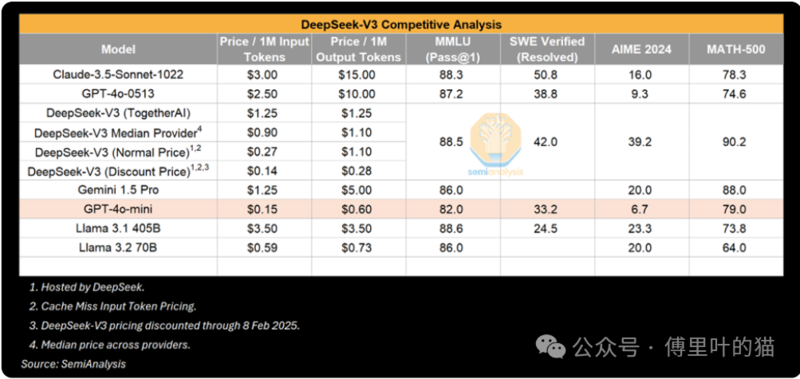
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見