-
日期: 2025-02-06 | 來源: 新智元 | 有0人參與評論 | 專欄: 哈佛 | 字體: 小 中 大
DeepSeek的獨特之處在於,他們通過調度特定的SM(流式多處理器)來管理GPU通信。
DeepSeek會精細地控制哪些SM核心負責模型計算,哪些核心負責allreduce或allgather通信,並在它們之間進行動態切換。這需要極其高深的編程技巧。
DeepSeek為何如此便宜
在所有聲稱提供R1服務的公司中,定價都遠高於DeepSeek API,而且大多服務無法正常工作,吞吐量極低。
讓大佬們震驚的是,壹方面中國取得了這種能力,另壹方面價格如此之低。(R1的價格,比o1便宜27倍)
訓練為什麼便宜,上文已經提到。為什麼推理成本也這麼低呢?
首先,就是DeepSeek在模型架構上的創新。MLA這種全新的注意力機制,跟Transformer注意力機制不同。
這種多頭潛注意力,可以將注意力機制的內存占用減少大約80%到90%,尤其有助於處理長上下文。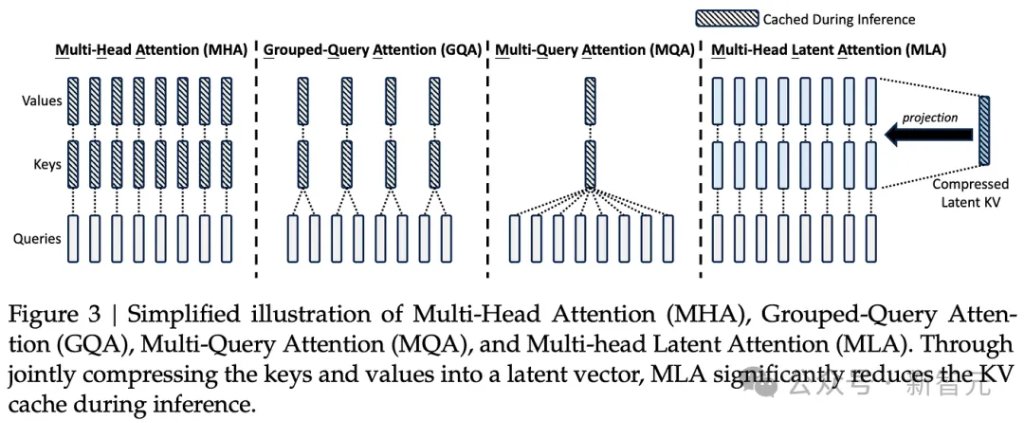
而且,DeepSeek和OpenAI的服務成本有巨大差異,部分原因是OpenAI的利潤率非常高,推理的毛利率超過了75%。
因為OpenAI目前是虧損的,在訓練上花費了太多,因此推理的利潤率很高。
接下來亮點來了,幾位大佬放飛想象,猜測這會不會是壹種陰謀論:DeepSeek精心策劃了這次發布和定價,做空英偉達和美國公司的股票,配合星際之門的發布……
但這種猜測立馬遭到了反駁,Dylan Patel表示,他們只是趕在農歷新年前把產品盡快發布而已,並沒有沒有打算搞個大的,否則為什麼選在聖誕節後壹天發布V3呢?
中國的工業能力,已經遠超美國
美國無疑在GPU等芯片領域領先於中國。
不過,對GPU出口管制,就能完全阻止中國嗎?不太可能。
Dylan Patel認為,美國政府也清楚地認識到這壹點, 而Nathan Lambert認為中國會制造自己的芯片。
中國可能擁有更多的人才、更多的STEM畢業生、更多的程序員。美國當然也可以利用世界各地的人才,但這未必能讓美國有額外的優勢。
真正重要的是計算能力。
中國擁有的電力總和,數量已經驚人。中國的鋼鐵廠,其規模相當於整個美國工業的總和,此外還有需要龐大電力的鋁廠。
即使美國的星際之門真的建成,達到2吉瓦電力,仍小於中國最大的工業設施。
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見