-
日期: 2025-02-27 | 来源: 新智元 | 有0人参与评论 | 字体: 小 中 大
尤其是在涉及高维度的整个上半身动作空间时,传统的手动机器人校准方法难以适用于大规模机器人群组。
为解决这一问题,Figure训练了一个视觉本体感知模型,该模型完全基于每个机器人自身的视觉输入来估计末端执行器的六自由度(6D)姿态。
这种在线“自我校准”机制使得跨机器人策略迁移能够高效进行,同时将停机时间降至最低。
数据筛选
数据方面,Figure在筛选时排除了那些速度较慢、失误或完全失败的人类示范。
但有意保留了一些自然包含纠正行为的示范,前提是造成失败的原因是环境的随机因素,而非操作者的错误。
与远程操作者密切合作,可以改进和统一操控策略,并带来显著的性能提升。
推理阶段操作加速
为了让系统能够接近并最终超越人类操作速度,Figure应用了一种简单但有效的测试阶段技术,从而实现了比示范者更快的学习行为――对策略动作块输出进行插值(“运动模式”)。
其中,S1策略输出动作“块”,即以200Hz频率执行的一系列机器人动作。
在实践中,可以在不修改训练程序的情况下实现20%的测试阶段加速。
方法是,将一个[T x action_dim]的动作块(表示一个T毫秒的轨迹)线性重采样为一个更短的[0.8 * T x action_dim]轨迹,然后以原始的200Hz控制率执行这个更短的动作块。
结果与讨论
使用标准化有效吞吐量* T_eff 来衡量系统性能,可以反映系统处理包裹的速度与训练数据中演示者速度的比值。(这一指标考虑到了系统重置所花费的时间)
例如,当T_eff > 1.1时,表示系统操作速度比训练所用的专家轨迹快10%。
立体视觉的重要性
图2(a)展示了多尺度特征提取器和立体视觉输入对系统T_eff的影响。
其中,多尺度特征提取和隐式立体输入显著提升了系统性能,立体视觉也显著增强了系统处理各种尺寸包裹的稳健性。
相比于非立体基线模型,立体模型实现了高达60%的吞吐量提升。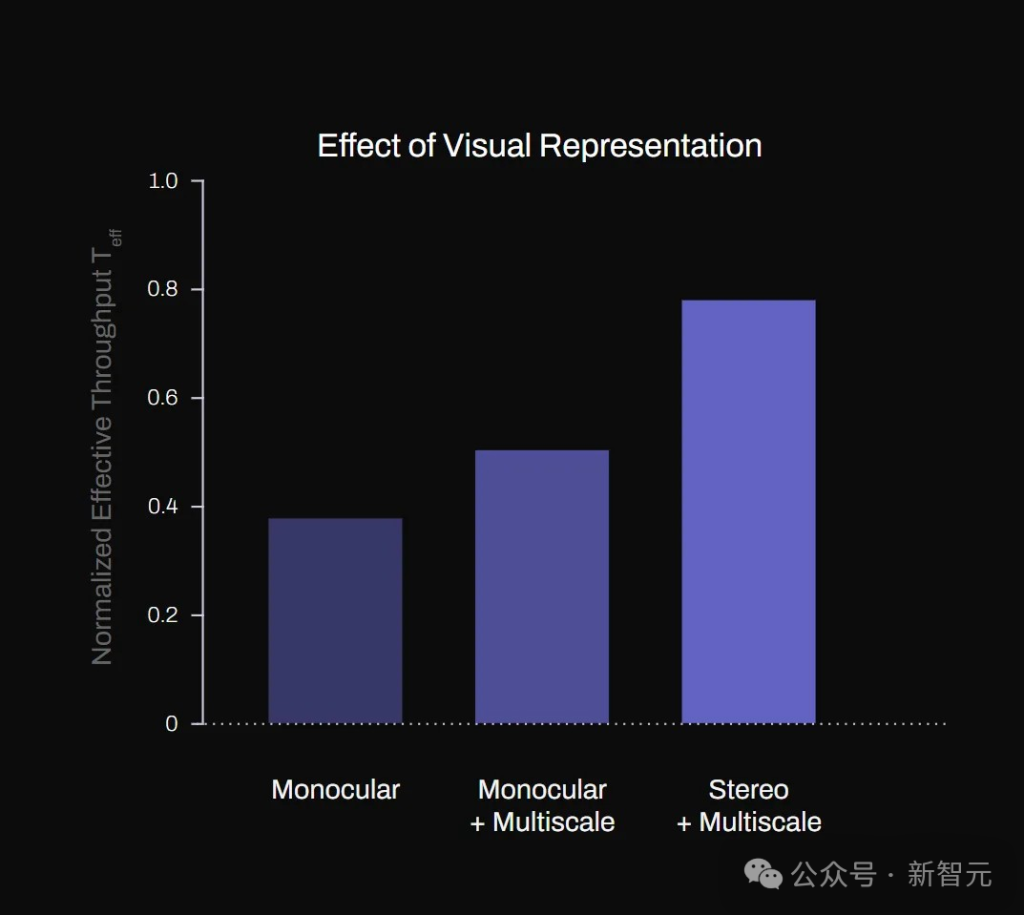
图2:(a)不同视觉表示方法对系统性能影响的消融研究
此外,配备立体视觉的S1系统能够成功处理系统从未训练过的平信封,表现出良好的泛化能力。
机器人可以将信封分拣出来。
可以看出机器人的手部活动十分灵活。
质量胜于数量
Figure发现,对于单个应用场景,数据质量和一致性比数据数量更为重要。
如图2(b)所示,尽避训练数据量减少了三分之一,但使用精心筛选的高质量示范数据训练的模型仍然实现了40%更高的吞吐量。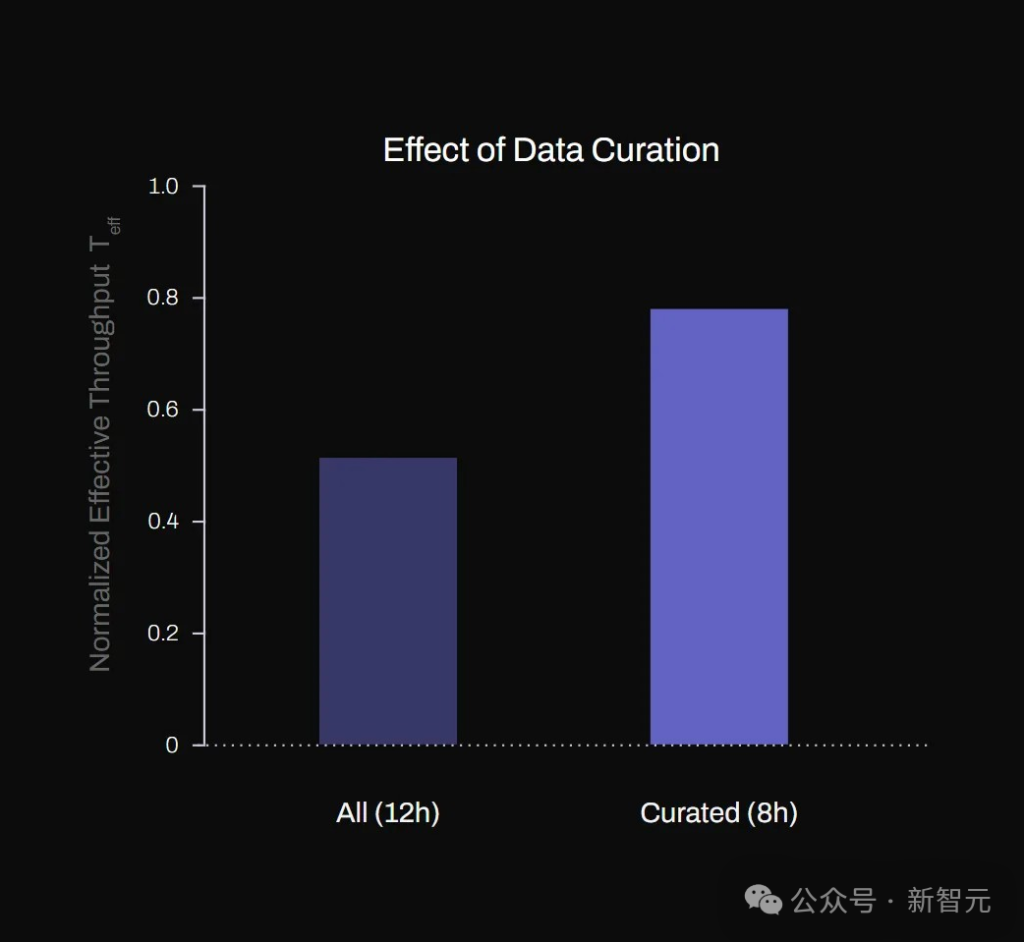
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见