-
日期: 2025-05-06 | 來源: 量子位 | 有0人參與評論 | 字體: 小 中 大
你以為大模型已經能輕松“上網沖浪”了?新基准測試集BrowseComp-ZH直接打臉主流AI。BrowseComp-ZH是壹項由港科大(廣州)、北大(专题)、浙大、阿裡、字節跳動、NIO等機構聯合發布的新基准測試集,讓20多個中外主流大模型集體“掛科”:
GPT-4o在測試中准確率僅6.2%;多數國產/國際模型准確率跌破10%;即便是目前表現最好的OpenAI DeepResearch,也僅得42.9%。
目前,BrowseComp-ZH的全部數據已開源發布。
研究團隊直言:
為什麼我們需要中文網頁能力測試?如今的大模型越來越擅長“用工具”:能連搜索引擎、能調用插件、能“看網頁”。
但眾多評估工具都只在英文語境下建立,對中文語境、中文搜索引擎、中文平台生態考慮甚少。
然而,中文互聯網信息碎片化嚴重、搜索入口多樣、語言表達復雜。
中文網頁世界到底有多難?舉幾個例子你就明白了:
信息碎片化,分散在百度百科、微博、地方政府網站、視頻號等多平台
常見的語言結構中含有省略、典故、代指,關鍵詞檢索常常“跑偏”
搜索引擎本身質量參差,信息“沉底”或“走丟”都是常事
因此,英文測試集“翻譯壹下”根本不夠。
需要從中文語境原生設計,才能真正衡量大模型是否能在中文網頁上“看得懂”、“搜得到”、“推得准”。
BrowseComp-ZH是怎麼煉成的?研究團隊采用了“逆向設計法”:從壹個明確、可驗證的事實答案出發(如某個畫種、機構、影視劇名),反向構造出多個約束條件的復雜問題,確保以下叁點:
百度/Bing/Google叁大搜索引擎首屏無法直接命中答案
多個主流大模型在檢索模式下也無法直接答對
經過人工驗證,問題結構清晰,且僅有唯壹答案
最終,他們構建了289道高難度中文多跳檢索題目,覆蓋影視、藝術、醫學、地理、歷史、科技等11大領域。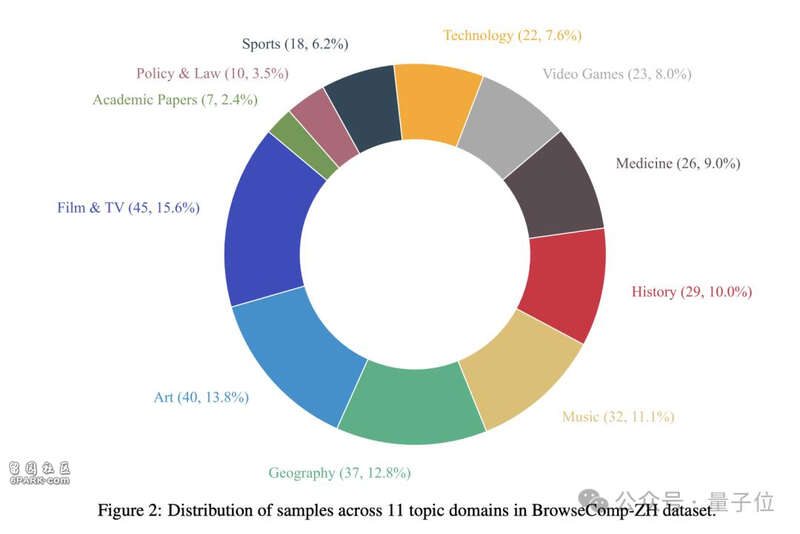

大模型集體“翻車”?DeepResearch勉強破肆成,絕大多數連10%都不到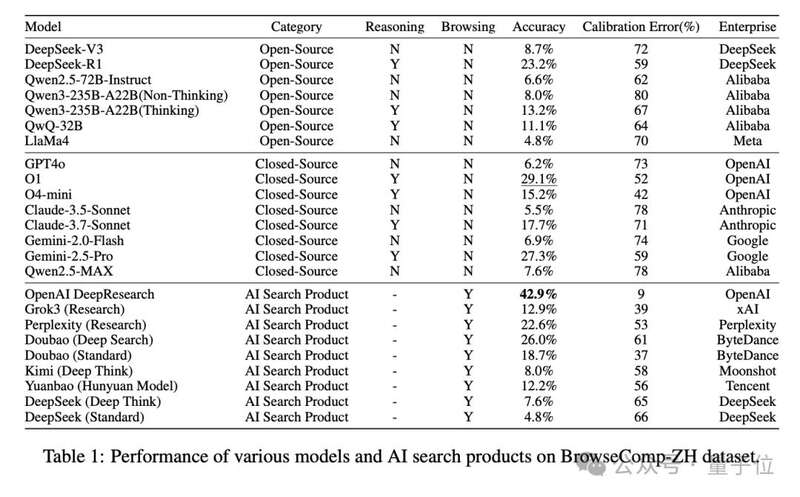
在BrowseComp-ZH的測試下,多款國內外主流大模型集體“翻車”:
盡管這些模型在對話理解、生成表達方面已展現強大實力,但在面對中文互聯網的復雜檢索任務時,准確率普遍低得驚人:
多數模型准確率低於10%,僅少數能突破20%
OpenAI DeepResearch以42.9%位列第壹,仍遠未“及格”
研究者指出,這壹結果說明:模型不僅需要會“查資料”,更要會“多跳推理”與“信息整合”,才能在中文互聯網中真正找到答案。
肆大發現,揭示中文網頁任務的“模型死角”1. 僅靠記憶不行,得真本事
純靠參數記憶(無搜索)的模型准確率往往低於10%,說明“硬背”不靠譜。
2. 有推理的模型,表現更好
DeepSeek-R1(23.2%)比DeepSeek-V3(8.7%)整整高出14.5%,Claude-3.7也比Claude-3.5提升了12.2%,推理能力成為關鍵變量。
3. 搜得多 ≠ 搜得准,多輪策略才是王道
具備多輪檢索能力的AI搜索產品全面勝出:
DeepResearch:42.9%
豆包Deep Search:26.0%
Perplexity Research模式:22.6%
相比之下,只檢索壹次的模型(如Kimi、Yuanbao)准確率低至個位數。
4. 搜索功能“翻車”?接入反而變差
最典型的反例是DeepSeek-R1,開啟搜索功能後准確率從23.2%斷崖式跌至7.6%。
研究指出,模型未能將網頁檢索信息與已有知識有效融合,反而被誤導。
數據集開放!歡迎模型開發者挑戰BrowseComp-ZH的全部數據已開源發布。
研究者希望此基准測試能成為推動LLM在中文信息環境落地的試金石,助力構建真正“會用中文上網”的智能體。
下壹步,他們計劃擴充樣本規模,拓展問答形式,並深入分析模型推理路徑與失敗案例。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見