-
日期: 2025-05-08 | 来源: 量子位 | 有0人参与评论 | 专栏: 华为 | 字体: 小 中 大
计算卸载与数据共享:当遇到NPU处理起来效率低的数据计算,或者在TP区域内数据传输慢的情况,作者把这些不适合NPU的计算从主计算流程中分离出来,交给CPU在数据加载时处理。再结合数据共享技术,让同一节点内的计算和数据传输速度都大大提高。
融合算子:除了盘古稠密模型里已有的FlashAttention 和 RMSNorm融合算子,团队在MoE模型里又加入了 GMMAdd、Permute和Umpermute融合算子。GMMAdd融合算子把GroupedMatMul的反向计算和梯度累加放在一起处理,利用并行和流水线技术减少调度时间。Permute和Unpermute融合算子整合了多种操作,能更快地读写内存。
实验结果
在训练数据集构建过程中,团队实施严格的数据质量控制,并着重强调语料库的多样性、复杂性和全面性。
针对长链思维样本引入特殊标记符号对推理轨迹与最终答案进行结构化分隔。
后训练阶段采用指令微调策略,数据涵盖领域广泛,包含通用问答、文本生成、语义分类、代码编程、数理逻辑推理及工具使用等。
特别将推理与非推理样本比例设定为3:1,进一步提升推理性能。
实验表明,盘古Ultra MoE对话版本在多领域均展现出卓越竞争力,在大多数benchmark上与DeepSeek-R1表现相当。比如通用理解任务(如CLUEWSC 94.8分、MMLU 91.5分)中展现卓越理解力,在数学推理与代码生成等高难度测试(如AIME2024 81.3分、MBPP+ 81.2分)中表现优异,具备突出的代码与数学解题能力。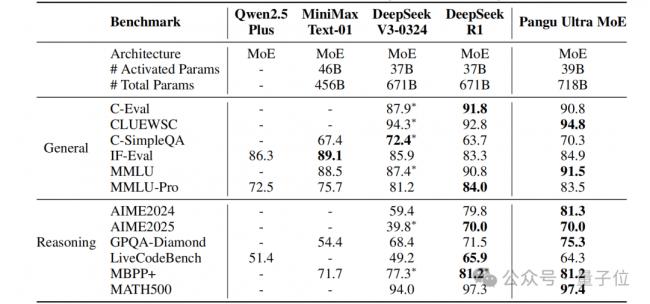
团队还对盘古Ultra MoE进行了专家专业度分析。
在不同任务中,同一网络层的token会被优先路由至不同专家,专家专业化程度存在显著任务差异性。
这证实了盘古Ultra MoE已形成显著的专家差异化,这种特性不仅增强了模型的表达能力,更为其卓越性能提供了关键支撑。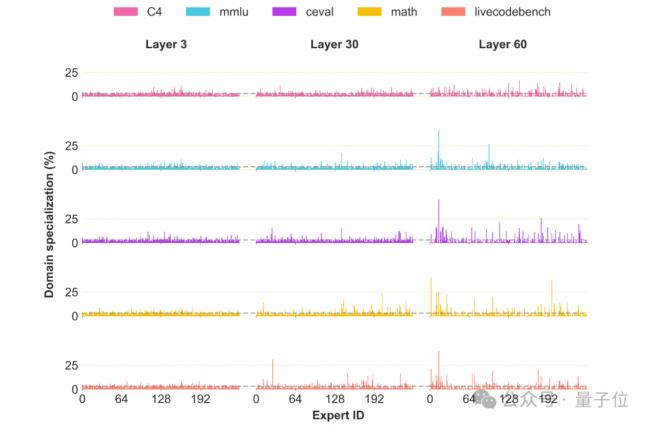
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见