-
日期: 2025-05-08 | 来源: 量子位 | 有0人参与评论 | 专栏: 华为 | 字体: 小 中 大
盘古Ultra MoE的MoE层输出由共享专家和路由专家共同贡献的加权和构成。
因此,保持二者输出的平衡至关重要。
下图中展示了路由专家在各网络层均保持着与共享专家相当的贡献强度,这种均衡的协同作用有效提升了模型的整体表征能力。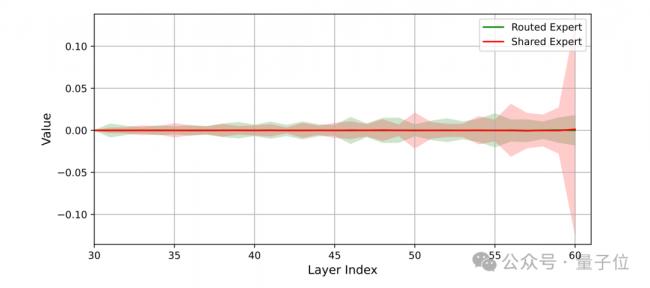
团队还分析了专家的共激活现象,激活分数越高,说明两个专家之间的相关性越强。
在下图中,除少数例外情况外,这三层中的专家之间并未出现明显的共激活现象,这反映了盘古Ultra MoE的专家冗余度较低。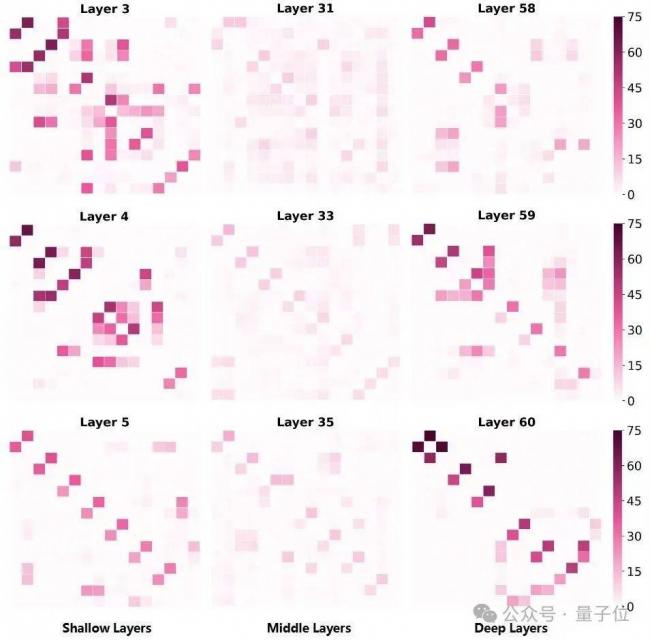
以上便是华为国产NPU跑准万亿参数大模型背后的奥义了。
华为盘古Ultra MoE技术的突破,不仅标志着国产算力平台在AI大模型训练领域迈入世界领先行列,更彰显了中国科技自主创新的强大实力。
它证明了中国企业在全球AI竞赛中已具备从跟跑到并跑,甚至领跑的实力。- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见