-
日期: 2025-05-14 | 來源: 華爾街日報 | 有0人參與評論 | 字體: 小 中 大
瓦法自己的研究是探索人工智能在接受數百萬次類似谷歌地圖那種逐個提示轉彎的導航訓練之後,會構建出什麼樣的心智地圖。瓦法和同事使用了曼哈頓密集的街道網絡作為原始材料。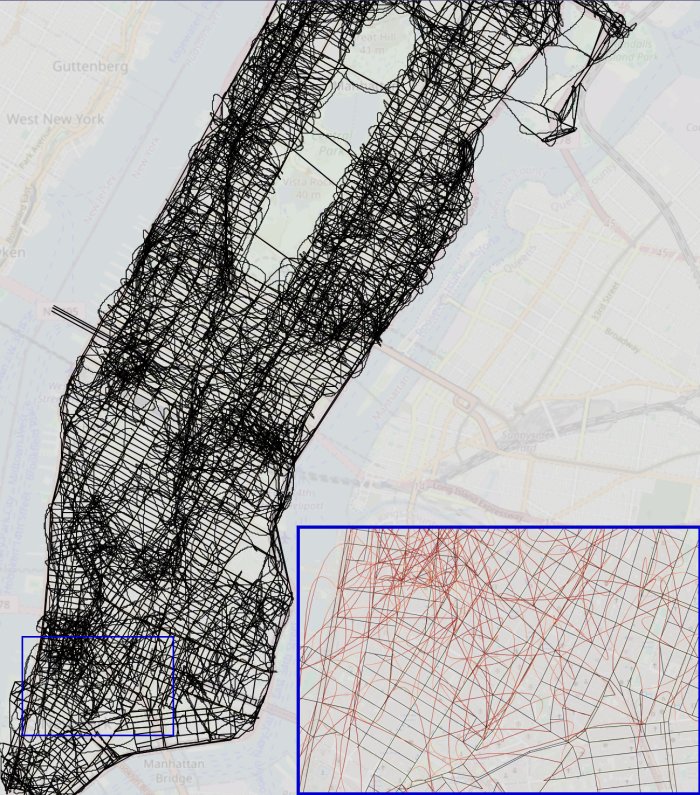
AI在經過數百萬條逐個轉彎路線的訓練後,在其“思維”中生成的曼哈頓地圖。該研究成果來自於Keyon Vafa、Justin Y. Chen、Ashesh Rambachan、Jon Kleinberg和Sendhil Mullainathan的論文《評估生成式AI模型中隱含的世界模型》(Evaluating the World Model Implicit in a Generative Model)。
結果看起來壹點也不像曼哈頓的街道地圖。經過仔細觀察,研究者發現人工智能推斷出了各種脫離現實的機動路線,比如直接越過中央公園或斜穿許多街區的路線。但由此產生的模型成功給出了曼哈頓區任意兩點之間可用的逐個轉彎路線,准確率高達99%。
瓦法說,盡管這張亂柒八糟的地圖會讓駕車者抓狂,但人工智能模型已經基本學會在多種情況下從每壹個可能的起點出發進行導航的單獨規則。
人工智能龐大的“大腦”加上前所未有的處理能力,使它們能夠學會如何以壹種雜亂無章的方式來解決問題,而這是人類不可能做到的。
思考還是記憶?
還有壹些研究關注大語言模型嘗試進行數學運算時所表現出的特殊性,這些模型從前不擅長數學運算,但現在的表現越來越好。壹些研究表明,模型在做某個數值范圍內的乘法,比如200到210之間數字的乘法時,會學習壹套單獨的規則,在做其他數值范圍內的乘法時,則會學習另壹套規則。如果你認為這種數學運算方式不太理想,那你說得沒錯。
這方面的研究都表明,在引擎蓋下,今天的人工智能是過於復雜、拼拼湊湊的魯布·戈德堡機械,其中充滿了回答我們提示的臨時性解決方案。瓦法說,如果理解了這些系統是壹長串拼湊在壹起的經驗法則,就能很好地解釋,為什麼當它們被要求做未經訓練的事情,哪怕只是超出訓練范圍壹丁點的事情,也會非常困難。當他的團隊阻斷僅1%的曼哈頓虛擬道路,迫使人工智能繞道而行,人工智能的表現便直線下降。
他補充說,這說明了今天的人工智能與人類之間的壹項重大差異。人可能無法以99%的准確率記住紐約市內的每壹處轉彎,但人的思維足夠靈活,可以避開壹些道路作業。
這項研究還揭示出為什麼許多模型都如此龐大:它們必須記住無窮無盡的經驗法則,而無法像人壹樣,把知識濃縮到心智模型中。這或許也有助於解釋,為什麼人工智能必須從海量的數據中學習,而人只需要經過幾次嘗試就能掌握知識:為了得出這壹條條經驗法則,它們必須看到單詞、圖像、棋盤位置等所有可能的組合。而要想真正訓練好人工智能模型,需要讓它們反復看這些組合。
這項研究或許還能解釋,為什麼不同公司推出的人工智能似乎都在以同樣的方式“思考”,甚至性能水平也在趨同——而這種性能水平的發展可能趨於停滯。
以前的人工智能研究者也曾信心滿滿。1970年,麻省理工學院(Massachusetts Institute of Technology)教授馬文·明斯基(Marvin Minsky)告訴Life雜志,“叁到八年後”,計算機將擁有普通人的智力。
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見