-
日期: 2025-09-08 | 來源: 新智元 | 有0人參與評論 | 字體: 小 中 大
甚至是那些專門設計來同時考察「專業知識與強推理能力」的最新基准,也出現了快速突破。
壹個典型例子是Humanity’s Last Exam):
在該基准上,OpenAI GPT-4o的得分僅2.7% ,而xAI Grok 4卻提升到 25.4%;
結合工具使用等優化手段後,結果甚至能進入40–50%區間。
然而,我們仍然發現壹些對人類而言輕而易舉的任務,AI表現不佳。
因此,出現了SimpleBench以及ARC-AGI這類基准,它們被專門設計為:對普通人來說很簡單,但對LLM卻很難。
ClockBench正是受這種「人類容易,AI困難」的思路啟發而設計。
研究團隊基於壹個關鍵觀察:對推理型和非推理型模型來說,讀懂模擬時鍾同樣很難。
因此,ClockBench構建了壹個需要高度視覺精度和推理能力的穩健數據集。
ClockBench究竟包含什麼?
36個全新設計的定制表盤,每個表盤生成5個樣本時鍾總計180個時鍾,每個時鍾設置4個問題,共720道測試題測試了來自6家實驗室的11個具備視覺理解能力的模型,並招募5名人類參與者對比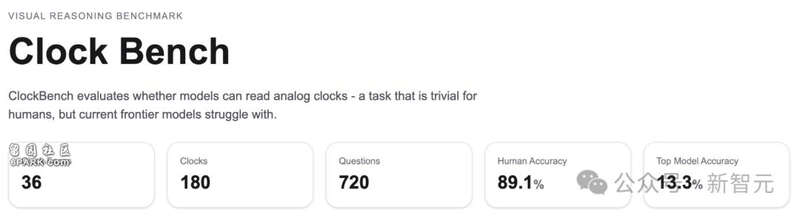
問題分為4大類:
1. 判斷時間是否有效
有壹個時鍾?,大模型需要判斷這個時鍾顯示的時間是不是有效的。
如果時間是合法的,大模型需要把它分解成幾個部分,並以JSON格式輸出:
小時 (Hours)、分鍾 (Minutes)、秒 (Seconds)、日期 (Date)、月份 (Month)、 星期幾 (Day of the week)- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見