-
日期: 2025-09-08 | 來源: 新智元 | 有0人參與評論 | 字體: 小 中 大
不過,也出現了壹些值得注意的現象:
谷歌的Gemini 2.5系列模型在各自類別中往往領先於其他模型;Anthropic系列模型則普遍落後於同類模型;Grok 4的表現遠低於預期,與其規模和通用能力並不相稱。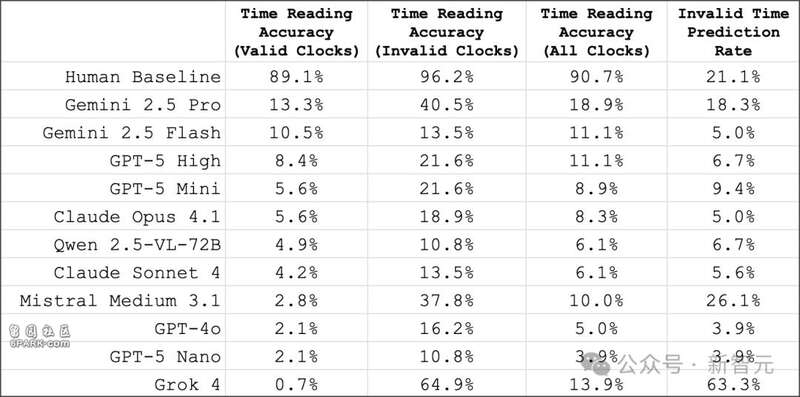
GPT-5排名第叁,且推理預算對結果影響不大(中等與高預算得分高度接近)值得思考的是:何種因素制約了GPT-5在此類視覺推理任務的表現?
在原始數據集中,180個時鍾裡有37個屬於無效(不可能存在)的時間。無論是人類還是模型,在識別「無效時間」時的成功率都更高:
人類差異不大:在無效時鍾上的准確率為96.2%,而在有效時鍾上為89.1%;模型差異明顯:在無效時鍾上的准確率平均高出349%,並且所有模型在這類任務中的表現都更好;Gemini 2.5 Pro依舊是總體最佳模型,准確率達到40.5%;Grok 4則是壹個異常值:它在識別無效時鍾上的准確率最高,達到64.9%,但問題在於,它把整個數據集裡63.3%的時鍾都標記為無效,這意味著結果很可能是「隨機撞對」。在模型能夠正確讀時的鍾面上,存在明顯的重疊現象:
61.7%的時鍾沒有被任何模型正確讀出;38.3%的時鍾至少被1個模型讀對;22.8%的時鍾至少被2個模型讀對;13.9%的時鍾至少被3個模型讀對;8.9%的時鍾至少被4個或以上的模型讀對。整體來看,分布情況和有效性數據表明:模型的正確答案集中在某壹小部分時鍾上,而不是均勻分布。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見