-
日期: 2025-09-08 | 來源: 新智元 | 有0人參與評論 | 字體: 小 中 大
90%人都會的讀鍾題,頂尖AI全軍覆沒!
AI基准創建者、連續創業者Alek Safar推出了視覺基准測試ClockBench,專注於測試AI的“看懂”模擬時鍾的能力。
結果讓人吃驚:
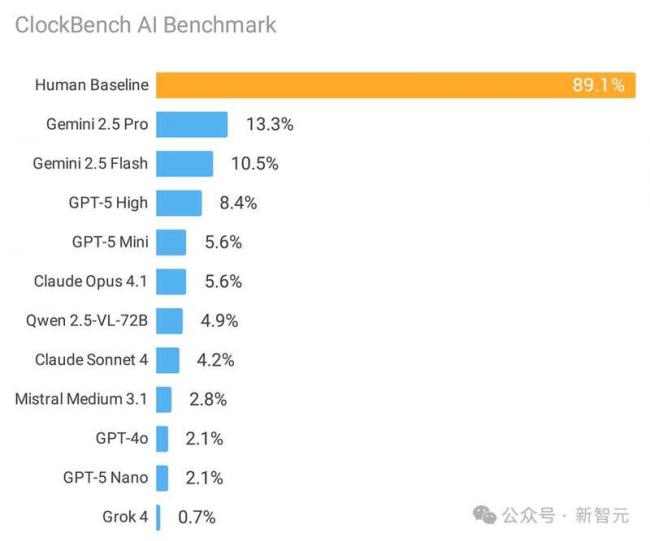
人類平均准確率89.1%,而參與測試的11個主流大模型最好的成績僅13.3%。
就難度而言,這與“AGI終極測試”ARC-AGI-2相當,比“人類終極考試”更難。
ClockBench共包含180個時鍾、720道問題,展示了當前前沿大語言模型(LLM)的局限性。
雖然這些模型在多項基准上展現出驚人的推理、數學與視覺理解能力,但這些能力尚未有效遷移到“讀表”。可能原因:
訓練數據未覆蓋足夠可記憶的時鍾特征與時間組合,模型不得不通過推理去建立指針、刻度與讀數之間的映射。
時鍾的視覺結構難以完整映射到文本空間,導致基於文本的推理受限。
也有好消息:表現最好的模型已展現出壹定的視覺推理(雖有限)。其讀時准確率與中位誤差均顯著優於隨機水平。
接下來需要更多研究,以判定這些能力能否通過擴大現有范式(數據、模型規模、計算/推理預算)來獲得,還是必須采用全新的方法。
ClockBench如何拷打AI?
在過去的幾年裡,大語言模型(LLM)在多個領域都取得了顯著進展,前沿模型很快在許多流行基准上達到了“飽和”。
甚至是那些專門設計來同時考察“專業知識與強推理能力”的最新基准,也出現了快速突破。
壹個典型例子是Humanity’s Last Exam):
在該基准上,OpenAI GPT-4o的得分僅2.7% ,而xAI Grok 4卻提升到 25.4%;
結合工具使用等優化手段後,結果甚至能進入40–50%區間。
然而,我們仍然發現壹些對人類而言輕而易舉的任務,AI表現不佳。
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見