-
日期: 2025-09-08 | 來源: 新智元 | 有0人參與評論 | 字體: 小 中 大
因此,出現了SimpleBench以及ARC-AGI這類基准,它們被專門設計為:對普通人來說很簡單,但對LLM卻很難。
ClockBench正是受這種“人類容易,AI困難”的思路啟發而設計。
研究團隊基於壹個關鍵觀察:對推理型和非推理型模型來說,讀懂模擬時鍾同樣很難。
因此,ClockBench構建了壹個需要高度視覺精度和推理能力的穩健數據集。
ClockBench究竟包含什麼?
36個全新設計的定制表盤,每個表盤生成5個樣本時鍾總計180個時鍾,每個時鍾設置4個問題,共720道測試題測試了來自6家實驗室的11個具備視覺理解能力的模型,並招募5名人類參與者對比。
問題分為4大類:
1. 判斷時間是否有效
有壹個時鍾️,大模型需要判斷這個時鍾顯示的時間是不是有效的。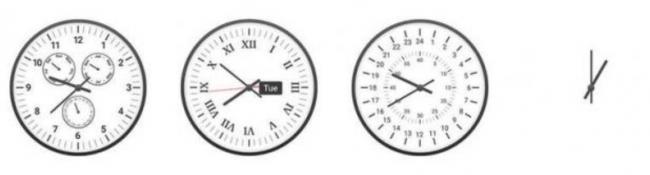
如果時間是合法的,大模型需要把它分解成幾個部分,並以JSON格式輸出:
小時 (Hours)、分鍾 (Minutes)、秒 (Seconds)、日期 (Date)、月份 (Month)、 星期幾 (Day of the week)
只要表盤包含上述信息,就要求LLM壹並輸出。
2. 時間的加減
該任務要求LLM對給定時間進行加減,得到新時間。
3. 旋轉時鍾指針
這個任務是關於操作時鍾的指針。該任務要求模型選擇時/分/秒針,並按指定角度順時針或逆時針旋轉。
4. 時區轉換
這個任務是關於不同地方的時間。比如,給定紐約的夏令時,模型需推算不同地點的當地時間。
結果出乎意料
結果有哪些出乎意料的發現?
模型與人類不僅正確率差距巨大,錯誤模式也截然不同:
人類誤差中位數僅3分鍾,最佳模型卻高達1小時較弱模型的誤差約3小時,結合12小時制表盤循環特性,相當於隨機噪聲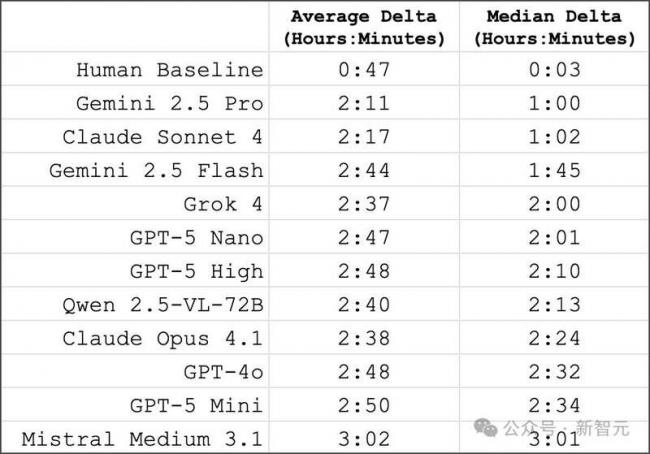
另壹個有趣發現是,某些鍾表特征的讀取難度存在顯著差異:
在讀取非常見的復雜鍾表及高精度要求場景時,模型表現最差羅馬數字與環形數字的朝向最難識別,其次是秒針、雜亂背景和鏡像時鍾- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見