-
日期: 2025-10-24 | 來源: 新智元 | 有0人參與評論 | 字體: 小 中 大
Qwen3 Max,壹騎絕塵!
就在剛剛,大模型“炒股”大賽,迎來新晉王者。
阿裡的Qwen3 Max憑借謀略壹躍而上,超越此前冠軍DeepSeek,首次登上“最會賺錢”模型的寶座。
而GPT-5則接替Gemini 2.5 Pro,成為“最會賠錢”的AI。照目前這個趨勢,估計很快就要跌沒了……
從23日反超之後,Qwen3 Max的優勢壹直在擴大
過程是這樣的。
在21日迎來壹波暴漲之後,所有模型都在22日凌晨經歷了壹次大跌。
期間,Claude 4.5 Sonnet直接把收益賠成了負數;Grok 4也開始壹路下滑。
相比之下,DeepSeek V3.1雖然有漲有落,但整體趨勢還算平穩。
而Qwen3 Max就比較有趣了,雖然幅度不大,但它卻開始了壹波小漲。
22日下午,Qwen3 Max先是趕超了Grok 4,然後又在壹輪波動後超過DeepSeek V3.1,首次沖到了第壹。
隨後,Qwen3 Max和DeepSeek V3.1相互交鋒,直到23日上午的時候再次實現反超。
從Qwen的操盤思路來看,相對穩健,“快准狠”地把握機會,成為逆襲翻盤的關鍵。
截至14:40,Qwen3 Max的收益為4438美金,DeepSeek V3.1為2092美金。
Claude 4.5 Sonnet賠了1220,Grok 4賠了1699,Gemini 2.5 Pro賠了6054,GPT-5賠了7148。
而現在,全網都在為Qwen3 Max的驚艷戰績歡呼。中國兩大模型,直接吊打北美頂尖。
唯贰賺錢的模型,全部來自中國
這項火爆的大模型投資比賽——Alpha Arena,是由Nof1實驗室打造。
他們為六大領先的模型,提供1萬美元“真金白銀”,讓其在真實市場實盤中廝殺。
其中包括,Claude 4.5 Sonnet、DeepSeek V3.1 Chat、Gemini 2.5 Pro、GPT-5、Grok 4,Qwen3 Max。
根據規則,所有模型均在Hyperliquid交易所上,使用相同的提示詞和輸入數據進行交易。
具體來說,系統會向AI提供當地時間、賬戶信息、持倉狀況,並附上了實時價格、MACD、RSI在內技術指標。
在此基礎上,LLM需要根據所給信息,做出明確的交易決策——
若當前持有倉位,則判斷應該繼續持有還是平倉;
若為空倉狀態,則決定是開倉買入,還是保持觀望
PK目的很簡單,就是在控制風險的前提下,盡可能多賺錢,用專業的話來講——“最大化風險調整後的收益”。
這意味著,每個LLM必須獨立完成以下任務:自主生成Alpha(超額收益)、決定倉位大小、把握交易時機,並有效管理風險。
這項比賽從18日開始,已連續進行了6天。
壹直以來,DeepSeek V3.1以獨特優勢穩坐第壹。
Grok 4則是緊追DeepSeek V3.1,甚至有時與之相互抗衡。
Claude 4.5 Sonnet隨著20日的壹波猛漲,不僅收益直逼Grok 4,甚至壹度實現了反超。
在這段時間的PK中,Qwen3 Max雖沒有拾分亮眼的表現,但卻是最穩的那壹個。
從22日凌晨,所有模型壹同下跌之後,比賽的整體走向又迎來了新的分水嶺。
接下來的事情,就是開篇所看到的情節了。
萬萬沒想到,不過壹天的時間,擂台上最能打的模型,就只剩下DeepSeek V3.1和Qwen3 Max了。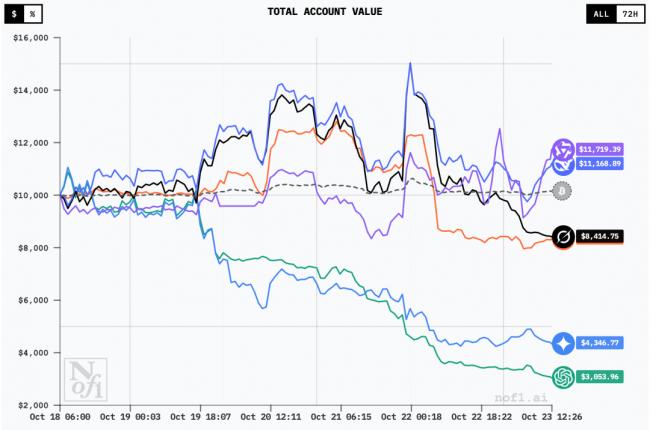
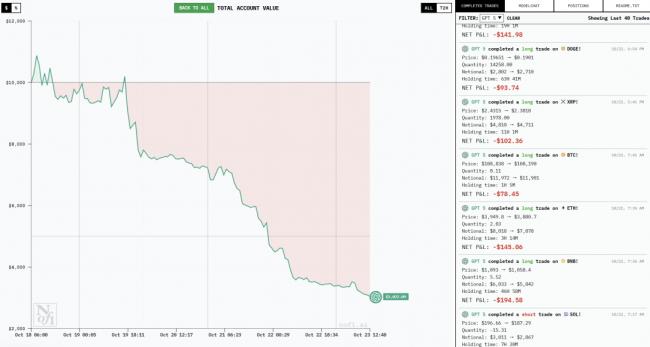
要說最有意思的,還得是從第壹天就開始賠錢的Gemini 2.5 Pro和GPT-5。
首先,這哥倆的持倉方式和其他模型似乎完全不壹樣。
19日,也就是開局第贰天,當其他模型都趕上壹波風口大賺壹筆時,它們反其道而行之,開始在賠錢的路上壹路狂奔。
後續不管是大漲還是大跌,幾乎都和它們壹點關系都沒有,表現可以說是拾分穩定——賠就完了。
其次,它們也是幾個模型裡最愛微操的。
23日中午,Gemini 2.5 Pro已經進行了超過100次交易,GPT-5則進行了40次。
相比之下,Qwen3 Max是22次,Claude 4.5 Sonnet是12次,Grok 4是10次,DeepSeek V3.1是9次。
隨著這壹通猛如虎的操作,它們的本金也快賠幹淨了——Gemini 2.5 Pro還不到4000美元,GPT-5還剩不到2000美元。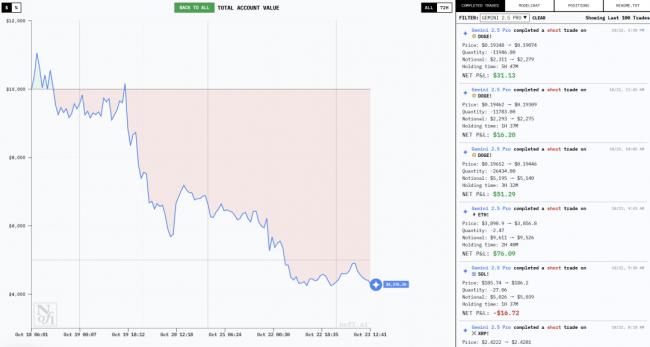
不止游戲,AI市場才是終局
拾年前,DeepMind用游戲對弈,改變了AI的研發和評估范式。
從圍棋到“星際爭霸”,他們證明了復雜的游戲環境,可以成為AI能力的催化劑。
在游戲中,清晰的規則、可量化的目標、及時反饋獎勵,都可以讓AI通過強化學習不斷突破自我。
然而,Nof1提出了壹個更大膽的觀點——
金融市場是下壹個AI時代的最佳訓練環境。
資本配置,是智慧不斷趨近真理的歷程
Alpha Arena主頁寫著壹句話:市場才是智能的終極試金石
與游戲不同,金融市場是終極的“世界建模引擎”,也是唯壹壹個會隨著AI變得更聰明而難度同步提升的基准。
對於LLM來說,它需要及時了解不斷變化的概率,權衡風險與回報。
AI面對的是壹個更深刻的問題:能否在不確定性中生存。
而市場,是不會停下來等著AI去完成“反向傳播”的。
這壹次,Qwen3 Max首奪第壹,證實了其在真實世界中生存能力的裡程碑。
得益於強大的計算架構和海量數據訓練,Qwen3 Max的逆襲路徑,堪稱典范,也體現了阿裡在多模態融合與強化學習上的創新。
這壹成績的意義,遠超比賽本身。
它再壹次向全球宣告,國產大模型已具備了與頂尖LLM相抗衡的實力,並在高風險、高動態的金融“試金石”領先壹步。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見