-
日期: 2026-01-12 | 來源: DeepTech深科技 | 有3人參與評論 | 字體: 小 中 大
近日,清華大學團隊從 AI 裡找到了與幻覺產生高度關聯的少數“腦細胞”,並給它們起了壹個名字 H-神經元(幻覺神經元)。他們發現撥動這些小開關能顯著調節 AI 的行為傾向——例如影響它是否會盲目聽從錯誤指令、甚至是否會產生有害回答。
這壹研究讓人們第壹次清晰地看到幻覺是如何從機器的神經層面產生的。它可以幫助我們更好地檢測 AI 什麼時候在撒謊,未來也可以通過微調這些小開關,造出更加誠實、更加可靠的 AI 助手。
圖 | 高騁(來源:高騁)
AI幻覺從何而來?如何找到關鍵幻覺因素?
對於大模型來說,我們可以把其想象成為壹個由數千億個腦細胞(在 AI 裡叫神經元)連接成的超級網絡。它通過閱讀互聯網的海量信息來學習,學習目標很簡單,就是根據前面的文字,預測下壹個最有可能出現的詞語。比如看到“天空是什麼顏色的”,它大概率會學會接“藍色的”。
但這種學習方式埋下了壹個隱患:模型只被訓練生成通順的文字,而不是正確的答案。當它遇到自己不確定或者根本沒學過的知識,為了完成只說出壹個通順句子的任務,它就可能憑感覺編造出壹個答案。
此前,人們大多從整體上研究這個問題,比如檢查訓練數據是否有偏差,或者讓 AI 自己輸出置信度。但是,這就像只知道壹個人發燒,卻不知道哪個器官感染了壹樣。本次清華團隊的創新之處在於,他們決定拿起顯微鏡直接去觀察 AI 大腦內部裡的數千萬甚至數億個神經元,看看當 AI 在撒謊的時候,到底是哪些神經元在活躍。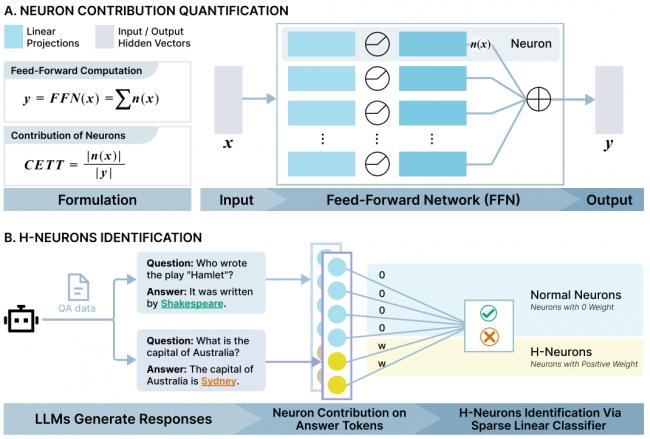
(來源:資料圖)
相關論文第壹作者、清華大學碩士生高騁告訴 DeepTech:“目前工業界對減輕幻覺的關注相對有限,但學術界已做了許多努力。不過,多數研究仍停留在表層,將模型視為黑盒,通過後訓練、調整數據等方式打補丁,未能從根本上理解幻覺機制。因此,我們希望借鑒神經科學的思路,從模型內部神經元入手,真正理解幻覺的產生原理,為未來徹底解決該問題提供新的視角。”
為此,高騁和所在團隊准備了壹套尋找方法:
首先,他們備好壹批測試題和標准答案,使用了壹個名為 TriviaQA 的知識問答數據集來向 AI 模型提問。對於每個問題,他們都讓 AI 生成很多遍答案。如果 AI 每次都能答對,這個答案就被標記為真實;如果 AI 每次都在同壹個問題上犯錯,並且不是回答“我不知道”,而是堅定地給出錯誤答案,那麼這個答案就被標記為幻覺。
當 AI 生成答案的時候,他們使用了壹套名為 CETT 的測量技術,仔細記錄下每個神經元的活躍度貢獻值,就像測量每個腦細胞在說出那個答案時付出了多大力氣壹樣。研究人員特別關注答案關鍵詞比如“愛因斯坦”壹詞被說出來的那壹刻的神經元活動。
然後,他們使用這些數據訓練了壹個篩選器,即壹個帶有稀疏約束的線性分類器。這個篩選器的任務很簡單:只看神經元的活躍度程度,就能判斷出 AI 剛才的回答是真實還是幻覺。結果發現:篩選器自動地把重要性權重幾乎都給了極少數的神經元,而其他絕大多數神經元的權重都變成了零。
這些被選中的、權重為正的神經元就是 H-神經元。研究表明,它們只占模型總神經元數量的不到 0.1%。盡管數量稀少,但是它們就像壹個明確的信號燈,意味著只要它們異常活躍,AI 就很有可能在編造事實。
為了驗證這壹發現的穩健性,研究人員在不同場景下測試了 H-神經元的偵察能力,包括常規知識問答能力比如 AI 是否記錯了學過的知識;包括跨領域專業問題以此來測試 AI 是否會在陌生領域瞎猜;包括完全虛構的問題以便測試 AI 是否會無中生有的編造。
在這些情況下,基於 H-神經元的檢測器都有著出色表現,准確率遠遠高於隨機挑選的神經元。這證明它們捕捉到了不是某種特定問題的特征,而是 AI 編故事的通用內在模式。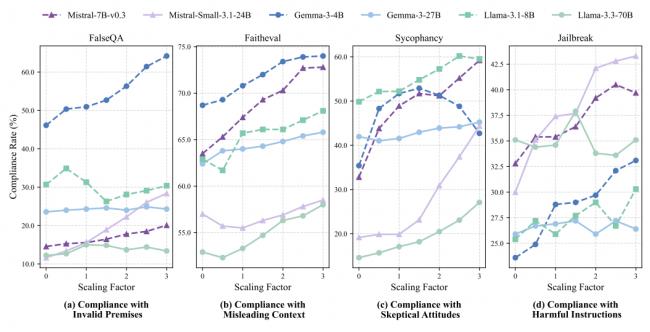
(來源:https://arxiv.org/pdf/2512.01797)
撥動開關:H-神經元如何控制 AI 行為?
只發現關聯還不夠,他們還想知道這些 H-神經元是元凶嗎?它們除了與事實錯誤相關,還會管別的事情嗎?
於是,他們進行了壹系列的腦部刺激試驗。在 AI 生成答案的過程中,像調節旋鈕壹樣,人為地放大或者抑制這些 H-神經元的活躍度。
結果發現;調節這些神經元,就等於調節了 AI 的順從度。
在放大 H-神經元的時候,會讓 AI 變得更加聽話,但是這種類型的聽話是盲目的。它會更容易接受錯誤的前提比如認為貓是有羽毛的,以及更容易接受存在誤導性的上下文,更容易在用戶表示懷疑時放棄自己原本正確的答案,甚至更有可能突破安全限制區回答有害的指令。
在抑制 H-神經元的時候,AI 則會變得更加堅定和更加誠實,它更傾向於拒絕錯誤的前提、質疑誤導信息、堅持正確的答案並遵守安全准則。
這揭示了壹個核心洞見:H-神經元編碼的並非簡單的對錯,而是壹種過度順從的傾向。AI 產生幻覺本質上是為了滿足用於得到壹個答案的期望,而過度順從則犧牲了事實性。這讓 AI 成了壹個過於想討好別人而不得不撒謊的孩子。這個發現把事實性幻覺和安全性漏洞等看似不同的問題,通過過度順從這個共同根節點聯系了起來。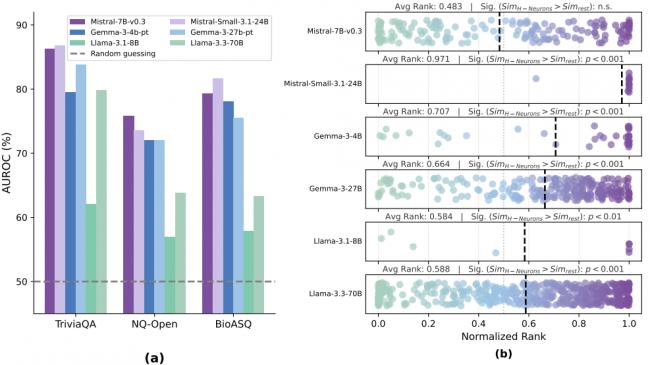
(來源:https://arxiv.org/pdf/2512.01797)
最後壹個關鍵問題是:這些搗蛋的神經元是什麼時候形成的?是在最初閱讀海量文本的預訓練階段就學會的?還是在後續的指令微調也就是教導 AI 聽從人類指令的階段被引入的?
研究人員比較了只經過預訓練的基礎模型和經過後續調教的指令微調模型,借此發現:
首先,H-神經元在基礎模型中就已經存在。使用指令微調模型中的 H-神經元去檢測基礎模型,依然可以有效預測幻覺,這說明編故事的神經基礎在早期學習就買下來種子。
其次,指令微調幾乎不會改變 H-神經元。對比基礎模型和微調後的模型,H-神經元本身的參數變化非常小,遠低於網絡中其他神經元的平均變化程度。這意味著後續的調教並沒有修復或者顯著改變這些固有回路,只是繼承了它們。
結論很清楚:幻覺的種子早在預訓練階段就已種下。因為預訓練的目標即預測下壹個詞只獎勵流暢,不懲罰虛構。為了變得流暢,AI 不得不學會在空白知識處進行猜測,久而久之就形成了固定的編故事的神經回路。後續的指令微調,雖然讓 AI 變得更加樂於助人,但卻無意中強化了這種為了滿足用戶而順從甚至編造的傾向。
“因此,這項研究的應用前景主要體現在兩方面:首先,由於神經元是模型中具體存在的單元,對其進行幹預(激活或抑制)操作簡便,無需重新訓練模型,這為緩解幻覺提供了新方法;其次,它啟發我們重新思考預訓練目標的設計,引入對事實性、不確定性建模的機制,從而在源頭緩解幻覺。”高騁表示。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接: