-
日期: 2026-02-01 | 来源: 智东西 | 有0人参与评论 | 字体: 小 中 大
时间线拉回到立项之前,当时智源研究院团队进行了大量分析和辩论,达成一个共识――多模态是未来实现AGI的关键路径,但现有的多模态生成长期以来由扩散模型主导,而视觉语言感知则主要由组合式方法引领,并不收敛统一,存在技术天花板。
尽管已有业内人士试图统一生成与感知(如Emu和Chameleon),但这些工作要么简单地将大语言模型与扩散模型拼接在一起,要么在性能效果上不及那些针对生成或感知任务精心设计的专用方法。
自回归架构能否作为原生统一多模态的技术路线,信与不信,这是一个重大的技术决策。最终在2024年2月底,智源研究院决定,组建一支五十人的技术攻关团队,以自回归架构为核心进行研发,并采用离散的token方式,以精简架构和大规模复用的大语言模型基础设施,开启全新的多模态模型Emu3的研发工作。
该模型开创性地将图像、文本和视频统一离散化到同一个表示空间中,并从零开始,在多模态序列混合数据上联合训练一个单一的 Transformer。
Emu3可完成不同多模态任务
这是一条挑战传统的“冒险”之路,在成功之前,智源研究院团队经历了重重挑战。
首先不言而喻的是技术上的挑战。选择“离散的token”方式本身是一种冒险,因为它尝试为视觉和其他模态重新发明一种与人类文字语言对齐的语言体系。在图像压缩过程中,由于图像信息相较于文字的信息量更大,但冗余更多,这使得基于token压缩图像时难以训练出有效模型,在这个过程中也难免受挫和沮丧。
第二,更深层次的是路径上的质疑。2024年国内各个大模型团队都在如火如荼地复现GPT-4,很多头部玩家一边也布局了多模态模型,但实际过程中存在摇摆,最终因资源消耗大、主线仍聚焦于语言模型等原因而砍掉了团队。智源研究院在这样的产业大背景下坚持了下来,背后需要一号位强大的信念和团队强大的定力。
第三,“多模态能否提升模型的智能”这个问题,当时还没有完全成定论。但智源团队坚信,下一代模型如果要进入到物理世界,仅靠文字是不够的,需要一个“见过世界”的模型。他们相信,不管突破多模态模型乃至世界模型智能升级有多难,它都是实现AGI的一条必经之路。
二、性能匹敌专用模型:两年,Emu3已深度影响产业发展脉络
多位业内专业人士告诉智东西,Emu3模型发布两年多以来,已经对多模态领域产生了显着影响,推动了整个产业的发展脉络。有证据表明其在产业界中得到了广泛应用和高度认可。
而进入产业应用的前提,是Emu3首先打赢了“性能”这一仗。在多模态生成与感知任务上,Emu3的整体表现可与多种成熟的任务专用模型相媲美。
首先聚焦文本到图像生成能力,在MSCOCO-30K23、GenEval24、T2I-CompBench25等多个基准上,Emu3的性能与当时最先进的扩散模型相当:超越了SD1.5、SDXL等模型,并接近DALL-E 3、FLUX.1(Dev)等模型。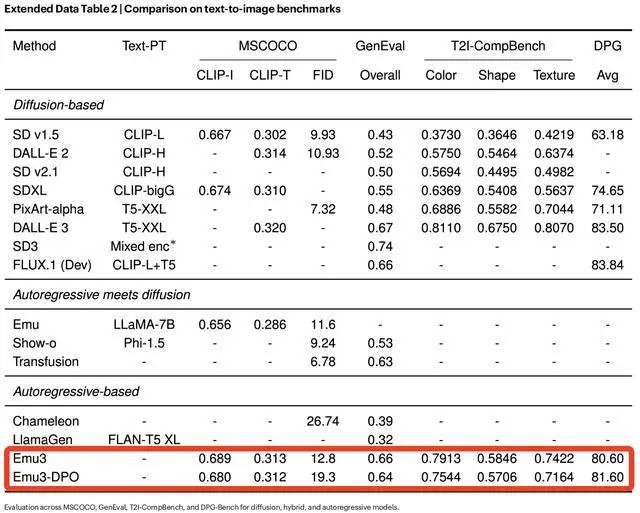
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见