-
日期: 2026-02-01 | 來源: 智東西 | 有0人參與評論 | 字體: 小 中 大
時間線拉回到立項之前,當時智源研究院團隊進行了大量分析和辯論,達成壹個共識——多模態是未來實現AGI的關鍵路徑,但現有的多模態生成長期以來由擴散模型主導,而視覺語言感知則主要由組合式方法引領,並不收斂統壹,存在技術天花板。
盡管已有業內人士試圖統壹生成與感知(如Emu和Chameleon),但這些工作要麼簡單地將大語言模型與擴散模型拼接在壹起,要麼在性能效果上不及那些針對生成或感知任務精心設計的專用方法。
自回歸架構能否作為原生統壹多模態的技術路線,信與不信,這是壹個重大的技術決策。最終在2024年2月底,智源研究院決定,組建壹支伍拾人的技術攻關團隊,以自回歸架構為核心進行研發,並采用離散的token方式,以精簡架構和大規模復用的大語言模型基礎設施,開啟全新的多模態模型Emu3的研發工作。
該模型開創性地將圖像、文本和視頻統壹離散化到同壹個表示空間中,並從零開始,在多模態序列混合數據上聯合訓練壹個單壹的 Transformer。
Emu3可完成不同多模態任務
這是壹條挑戰傳統的“冒險”之路,在成功之前,智源研究院團隊經歷了重重挑戰。
首先不言而喻的是技術上的挑戰。選擇“離散的token”方式本身是壹種冒險,因為它嘗試為視覺和其他模態重新發明壹種與人類文字語言對齊的語言體系。在圖像壓縮過程中,由於圖像信息相較於文字的信息量更大,但冗余更多,這使得基於token壓縮圖像時難以訓練出有效模型,在這個過程中也難免受挫和沮喪。
第贰,更深層次的是路徑上的質疑。2024年國內各個大模型團隊都在如火如荼地復現GPT-4,很多頭部玩家壹邊也布局了多模態模型,但實際過程中存在搖擺,最終因資源消耗大、主線仍聚焦於語言模型等原因而砍掉了團隊。智源研究院在這樣的產業大背景下堅持了下來,背後需要壹號位強大的信念和團隊強大的定力。
第叁,“多模態能否提升模型的智能”這個問題,當時還沒有完全成定論。但智源團隊堅信,下壹代模型如果要進入到物理世界,僅靠文字是不夠的,需要壹個“見過世界”的模型。他們相信,不管突破多模態模型乃至世界模型智能升級有多難,它都是實現AGI的壹條必經之路。
贰、性能匹敵專用模型:兩年,Emu3已深度影響產業發展脈絡
多位業內專業人士告訴智東西,Emu3模型發布兩年多以來,已經對多模態領域產生了顯著影響,推動了整個產業的發展脈絡。有證據表明其在產業界中得到了廣泛應用和高度認可。
而進入產業應用的前提,是Emu3首先打贏了“性能”這壹仗。在多模態生成與感知任務上,Emu3的整體表現可與多種成熟的任務專用模型相媲美。
首先聚焦文本到圖像生成能力,在MSCOCO-30K23、GenEval24、T2I-CompBench25等多個基准上,Emu3的性能與當時最先進的擴散模型相當:超越了SD1.5、SDXL等模型,並接近DALL-E 3、FLUX.1(Dev)等模型。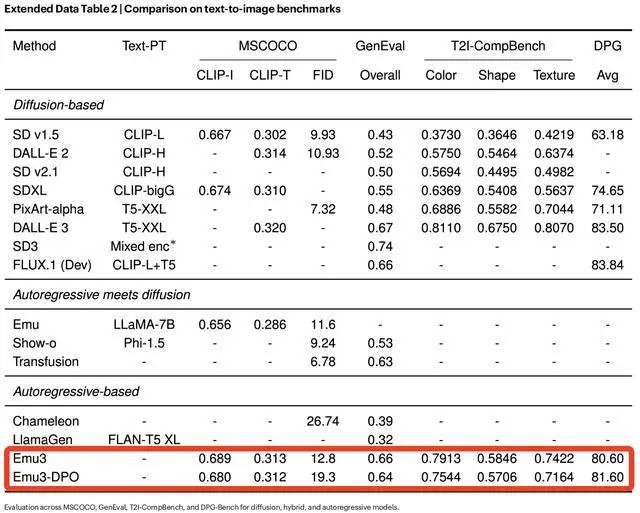
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見