-
日期: 2026-02-01 | 來源: 智東西 | 有0人參與評論 | 字體: 小 中 大
Emu3的性能與最先進的擴散模型相當
如下圖所示,在文生圖任務中,其效果達到擴散模型水平;在視覺語言理解方面,其可以與融合CLIP和大語言模型的主流方案比肩。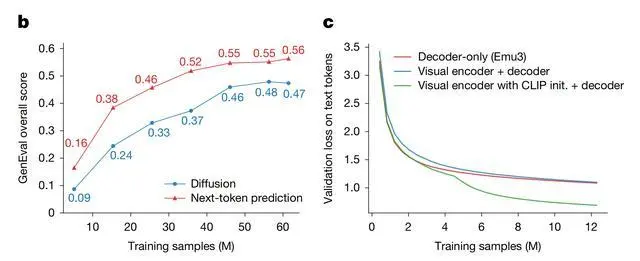
Emu3在文生圖和視覺語言理解上比肩主流方案
在視覺語言理解方面,如下圖所示,Emu3作為壹種純粹的無編碼器方法,在多個基准測試中達到了與其同類方法相當的性能。取得這樣的視覺-語言理解能力,Emu3並未依賴專門的預訓練大語言模型和CLIP。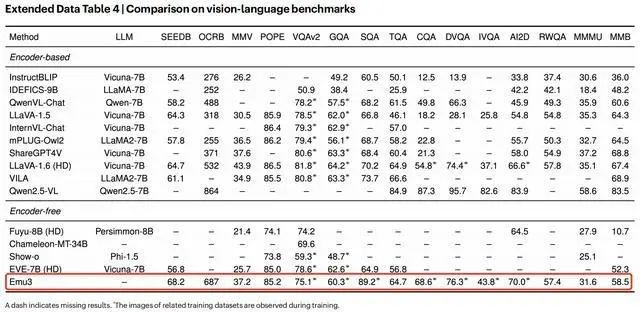
Emu3在視覺-語言理解能力方面的測評成績
在零樣本圖像修復案例中,給定輸入圖像(每行左側)和相應提示,Emu3能准確填充邊界框內的掩碼區域,生成語義對齊的內容,且無需特定任務的微調。
Emu3零樣本圖像修復
同時,Emu3還具備視頻生成能力。Emu3原生支持生成24幀/秒的5秒視頻,並可通過自回歸方法進行擴展。如圖所示,在擴展數據表3中,Emu3所產生的結果與其他視頻擴散模型相比具有很強的競爭力:Emu3的性能超過Open Sora V1.2、Kling(2024)、Gen-3等當年的知名專用模型。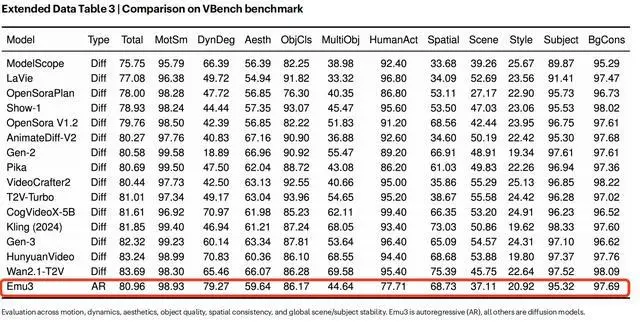
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見