-
日期: 2026-02-01 | 來源: 智東西 | 有0人參與評論 | 字體: 小 中 大
1、壹個大型的混合多模態訓練數據集。
2、壹個統壹的標記器,可將圖像和視頻片段轉換為緊湊的離散標記流(視覺分詞器)。
3、壹個基於Transformer的僅解碼器架構,該架構擴展了大型語言模型的嵌入空間以接受視覺標記,其他方面則遵循標准的僅解碼器設計選擇(架構)。
4、壹個兩階段優化方案,包括采用平衡交叉熵損失的大規模多模態預訓練,以及與任務格式和人類偏好對齊的高質量後訓練(預訓練和後訓練)。
5、壹個高效的推理後端,支持無分類器引導(CFG)、低延遲和高吞吐量,用於自回歸多模態生成(推理)。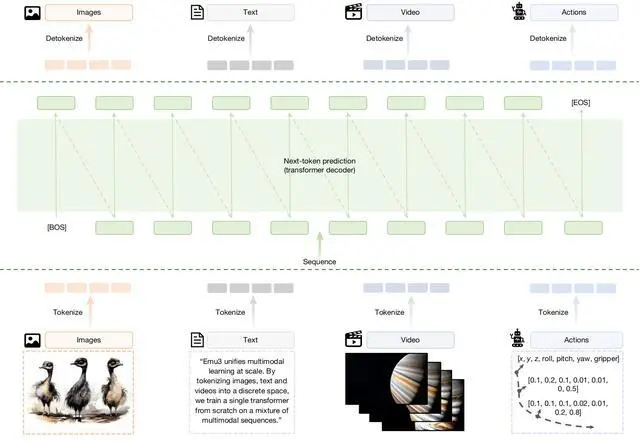
Emu3架構圖
這壹架構證明,僅憑“預測下壹個token”,我們就能夠同時支持高水平的生成能力與理解能力,並且在同壹統壹架構下,自然地擴展到機器人操作以及多模態交錯等生成任務。智源研究團隊對相關研究的多項關鍵技術與模型進行了開源,以推動該方向的持續研究。
同時,研究通過大規模消融實驗系統分析了多項關鍵技術的設計選擇,驗證了多模態學習的規模定律(Scaling law)、統壹離散化的高效性、以及解碼器架構的有效性。研究還驗證了自回歸路線高度通用性:直接偏好優化(DPO)方法可無縫應用於自回歸視覺生成任務,使模型能夠更好地對齊人類偏好。
在此研究基礎上,悟界·Emu3.5進壹步通過大規模長時序視頻訓練,學習時空與因果關系,展現出隨模型與數據規模增長而提升的物理世界建模能力,並觀察到多模態能力隨規模擴展而湧現的趨勢,實現了“預測下壹個狀態”的范式升級。
肆、堅持原始創新:北京智源引領大模型技術演進
自2018年創立之後,智源研究院通過多項成果深刻影響了中國AI學術和產業界。其在2021年發布了中國首個大語言模型“悟道1.0”,及當時全球最大的大語言模型(采用MoE架構)“悟道2.0”,同時因輸送大量頂尖AI產業人才被稱為“大模型的黃埔軍校”。
智源2022年開辟的新的模型系列——悟界·Emu研究成果的發表,不僅是國際學術界對智源研究團隊工作的認可,更是對中國AI原創技術路線的重要肯定。
Emu系列模型自2022年啟動研發以來,圍繞“原生多模態”這壹核心技術主線持續迭代,每壹個版本都在關鍵能力與方法論上實現了實質性突破。
2022年6月,系統布局多模態大模型的研發。
2023年7月,發布並開源首個版本,成為最早打通多模態輸入到多模態輸出的統壹多模態模型,創新性提出統壹多模態學習框架並大規模引入視頻數據,初步實現多模態自回歸預測。
2023年12月,發布Emu2,通過大規模自回歸生成式多模態預訓練,展現出可泛化的多模態上下文學習能力,可在少量示例和簡單指令下完成聽、說、讀、寫、畫等任務,是當時開源最大的生成式多模態模型。
2024年10月,發布Emu3,該模型只基於預測下壹個token,無需擴散模型或組合方法,即可完成文本、圖像、視頻叁種模態數據的理解和生成。
2025年10月,推出原生多模態世界模型Emu3.5,實現從 “預測下壹個token” 到 “預測下壹個狀態” 的能力躍遷,從長視頻數據中學習世界演化規律,提出多模態 Scaling 新范式。
自2020年啟動“悟道”大模型研究以來,智源持續聚焦大模型的原始創新與長期技術路徑探索。2025年6月,智源發布新壹代大模型系列“悟界”,旨在構建人工智能從數字世界邁向物理世界的關鍵能力,及物理世界的人工智能基座模型。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見