-
日期: 2026-03-08 | 來源: 極客公園 | 有0人參與評論 | 字體: 小 中 大
AI 已經學會了電影的視覺語法,但還沒學會世界的物理語法。

頭圖來源:Nano Banana
作者|湯壹濤
編輯|靖宇
Seedance 2.0 有多猛,過去壹個月大家已經見識過了。好萊塢已經集體下場發了聲明,西半球最強法務部迪士尼也給字節跳動發了律師函。
但如果你讓它做壹件事:生成壹個男人從 1 數到 10 的視頻,它就露餡了。
生成出來的「人」伍官端正、皮膚質感逼真,廚房背景細節豐富得像是實拍。他說出「one」的時候還壹切正常,然後就開始鬼打牆,嘴裡不斷重復「t、t、t」這個音節(不是從 1 到 10 中任何壹個數字的發音);或者伸出叁根手指,口中卻自信地說出「ten」。從頭到尾,他豎起的手指沒超過叁根。
因為背景和人物都太真實了,所以手指崩壞的瞬間反而制造出了壹種強烈的「偽人感」。
這道題不只是 Seedance 2.0 的噩夢。
視頻來自壹位在 X 網友 fofr(簡介顯示是在 DeepMind 的開發者)。去年他就發現,「從 1 數到 10 並用手指比出數字」這個對叁歲小孩都毫無難度的任務,是當前所有 AI 視頻模型的共同死穴。
Seedance 2.0 發布後,他第壹時間把這道老題扔了過去,果然也翻車了。
網友在這條推文下面掀起了壹場自發的「AI 數數挑戰賽」。他們把同壹道題喂給了 Sora、Veo、Kling 等幾乎所有主流模型,結果全軍覆沒,沒有壹個能正確地從 1 數到 10。
當壹個行業最強的產品們被壹道幼兒園級別的題目集體難倒,這其實指向了壹個問題:為什麼這些模型已經能騙過你的眼睛,卻無法理解常識?
它們到底「理解」了什麼,又缺失了什麼?
01統計預測 vs 理解世界:AI 視頻的能力邊界
「數不到 10」不是壹個孤立的 bug,它揭示了壹整片當前 AI 的能力盲區。
原因也不復雜:所有的視頻模型本質上做的是同壹件事,從海量視頻數據中學習統計規律,然後在生成每壹幀畫面時預測「接下來什麼樣的像素排列最可能出現」。這和大語言模型的「預測下壹個詞」(Next-Token Prediction)是同壹套邏輯。
所以它們能把人臉毛孔、廚房光影、衣服褶皺渲染得以假亂真,因為訓練數據裡有海量樣本,統計規律足夠豐富。但壹旦任務超出了樣本的范疇,進入「常識」的領域,問題就來了。
這些問題大致可以分成叁類。
首先就是手部精細動作,這是最廣為人知的「AI 照妖鏡」。從圖像生成時代的「六指人」,到視頻生成時代的「軟糖手指」,手壹直是 AI 的噩夢。
Midjourney 和 DALL-E 爆火的 2022 年,「手部多指」是當時文生圖最明顯的 Bug|圖片來源:Medium
公平地說,AI 在「畫手」這件事上已經取得了巨大進步。日常場景裡,六指人和軟糖手已經越來越少見了。
但 fofr 的測試之所以能讓所有模型集體翻車,是因為它只是壹個視覺渲染問題,同時還暗含了壹個邏輯推理問題。它要求在 10 秒內連續變換 10 個不同手勢,每個手勢的手指數量嚴格遞增,同時嘴裡說的數字還要對得上。
人的手有 27 塊骨骼、34 塊肌肉、超過 100 條韌帶,單個手掌就有 18 個自由度。即便采用高分辨率擴散模型,若缺乏明確的叁維先驗知識,也難以表達這種精確度。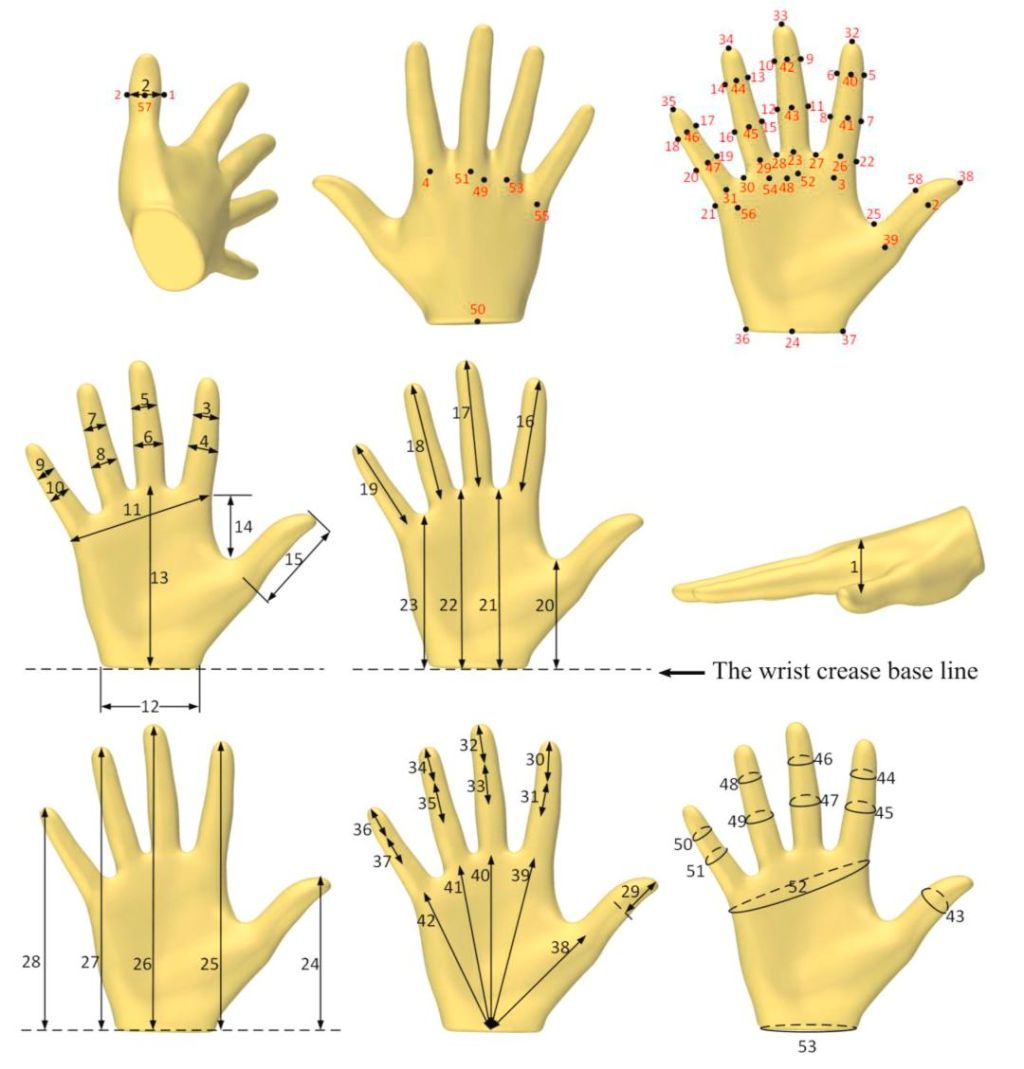
人體運動維度示意圖|圖片來源:ScienceDirect
況且,在訓練數據中,手通常出現在畫面邊緣、被物體遮擋或處於運動模糊中。模型能學到的高質量手部樣本遠少於面部。
第贰類 AI 的能力盲區是物理規律。流體怎麼流、物體怎麼碰撞、織物怎麼飄……這些人類靠直覺就能判斷的東西,AI 視頻經常給出違反物理定律的答案。OpenAI 在發布 Sora 時的官方技術報告中就明確承認:Sora 無法准確模擬許多基本物理交互,比如玻璃破碎,也無法正確反映某些物體狀態變化。
第叁類是時序邏輯的壹致性。視頻不是壹組彼此獨立的圖片,而是壹條有因果關系的時間鏈:第 3 秒的畫面必須建立在第 2 秒的基礎上。但當前的擴散模型把時間當作壹個潛在的數學維度來處理。它在生成第 N 幀時,沒有內部機制去「記住」前面伸了幾根手指、下壹步該加 1。時間壹長,前後就對不上了。
作個類比的話,當前的 AI 視頻模型像壹個從沒見過真手的畫家,看了壹百萬張手的照片之後憑印象畫手。大部分時候畫得挺像,但他不知道手指只有伍根,不知道伸出叁根手指代表數字 3,更不知道從 3 到 4 意味著要再伸出壹根。
02另壹條路:世界模型
既然問題的根源是「不理解物理世界」,那有沒有人在試圖從根本上解決這個問題?
事實上,這正在成為 AI 領域最受關注的新方向之壹。壹個正在凝聚共識的思路是:與其讓模型從海量視頻中學習「世界看起來是什麼樣的」,不如讓它先理解「世界是怎麼運作的」。
這條路徑有壹個共同的名字,叫做世界模型(world model)。世界模型的核心思路是讓 AI 建立對叁維物理世界的結構性理解,包括空間的幾何關系、物體的物理屬性、運動的動力學規律等。
這就和當前視頻生成模型的路徑產生了本質區別。當前模型在贰維平面上預測像素排列的統計概率,世界模型則試圖讓 AI 在「懂」物理規律的基礎上做生成。
這個方向最知名的創業者是李飛飛。這位 ImageNet 的締造者在 2024 年創辦了 World Labs,核心目標是讓 AI 擁有「空間智能」。她在去年的壹篇長文中寫道:
「語言是人類認知的產物,但世界遵循更復雜的規則——重力控制運動,原子結構決定光線如何產生顏色,無數物理定律約束著每壹次交互。要讓 AI 真正理解這壹切,需要壹種全新的、遠超大語言模型的架構」。
今年 2 月,World Labs 完成了 10 億美元融資,其首個產品 Marble 已經上線,可以從圖像或文本生成持久的 3D 環境。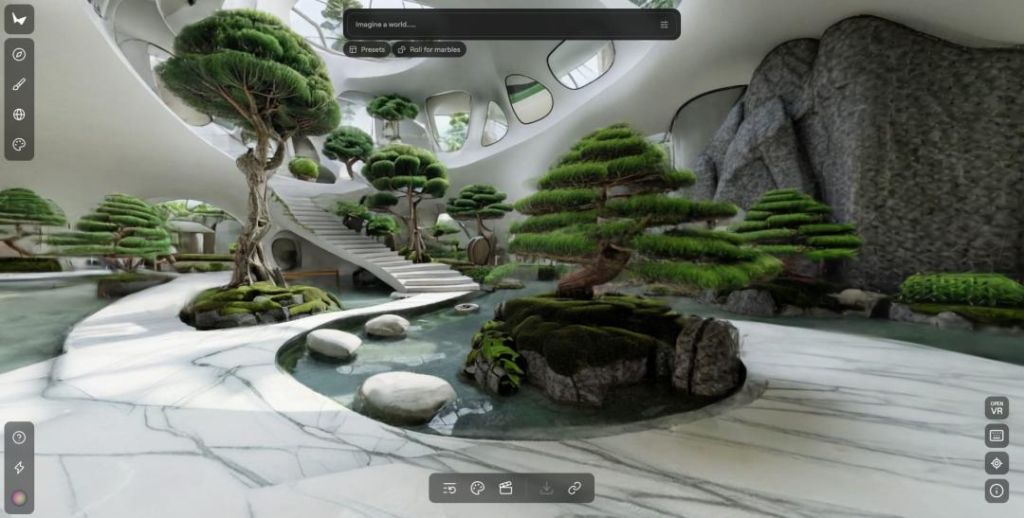
Marble 可以從壹張圖片或壹段文字生成壹個你能在裡面自由走動、持續編輯的 3D 世界|圖片來源:World Labs
李飛飛不是唯壹的入局者。楊樂昆從 Meta 離職後創辦了 AMI Labs,同樣聚焦世界模型方向;Google DeepMind 的 Genie 系列模型也在探索 3D 環境的生成與模擬;Nvidia 則推出了 Cosmos,定位為「世界基礎模型」,試圖將視頻生成、物理感知模擬和機器人工作流統壹到壹個框架裡。
當這個領域最頂級的幾位研究者和最有錢的幾家公司同時往壹個方向走,這本身就說明了壹些問題。純數據驅動路徑的天花板,正在成為越來越多人的共識,只是解法還在探索中。
Seedance 2.0 剛出來的時候確實引起了壹大波恐慌。《死侍》編劇 Rhett Reese 看完演示後甚至寫下了「我不想承認,但我們可能完了」。
這種反應可以理解,Seedance 2.0 確實很強,但「數不到 10」提供了壹個有用的校准視角:這些模型學會了電影的視覺語法,但還沒學會世界的物理語法。它們的進步,更多是「看起來更真」,而不是「更懂現實」。
從本質上說,壹個不知道手指只有伍根的系統,距離真正取代人類創作者,中間還隔著壹次范式級別的跨越。
人類可以稍稍松口氣了,至少在 AI 學會數到 10 之前。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見