-
日期: 2026-04-24 | 來源: 鈦媒體APP | 有0人參與評論 | 字體: 小 中 大
相比起問模型知不知道某項知識,現在更看重它能不能完成壹項完整工作。
這也對應了GPT-5.5本次的更新重點。模型開始能夠自主地組織步驟:先獲取信息,再做判斷,必要時調用工具,最後把結果整理成可以直接使用的輸出。
在編程上,它參與整個開發流程,而不只是生成代碼;在知識工作中,它產出報告、模型和決策建議,而不只是提供答案;在操作層面,它甚至可以直接進入電腦環境,把這些步驟執行出來。
這壹代模型更像壹個可以協作的執行者,得分只是表面,更重要的是這些分數背後指向的壹件事:GPT-5.5的定位,從“回答”轉向了“執行”。
順便壹提,根據ARC Prize官方驗證,GPT-5.5在ARC-AGI-2基准測試中取得最高85.0%的准確率,成為了新的SOTA模型。
除了能力本身,這壹代模型還有壹個被反復強調的點:效率。
OpenAI給出的數據是,在實際服務中,GPT-5.5的速度與GPT-5.4基本持平,但在完成同樣Codex任務時使用的token明顯更少。這壹點對API用戶尤其重要,因為它直接決定了真實使用成本。
在定價上,GPT-5.5 API為每百萬輸入token 5美元、輸出30美元,Pro版本更高。這個價格是GPT-5.4的兩倍。
不過OpenAI的邏輯是:單價雖然提升,但由於任務完成效率更高,總成本未必上升。
另外,安全體系也在同步升級:GPT-5.5是目前防護最嚴格的壹代模型,在發布前經歷了完整的安全評估流程,包括內部與外部紅隊測試,以及針對網絡安全、生物等高風險能力的專項驗證,並結合了近200個真實使用場景進行調整。
模型表現
作為壹個擅長復雜任務的模型,GPT-5.5的編碼優勢在Codex中表現尤為突出,可以完成從實現和重構到調試、測試和驗證等工程工作。
根據官方文檔,它在真實工程上表現很好:在大型任務中能夠持續保持上下文(不會只盯著壹小段代碼);在問題不明確時,能夠推理出故障原因;會用工具去驗證自己的假設;能把修改真正“貫穿”到整個代碼庫,而不是只改壹處。
官方給出了壹些比較復雜的示例,例如把壹張天體圖片重新做成壹個新的Web應用。
技術上要求用WebGL做3D渲染、用Vite搭項目,內容上要盡量接入ArtemisII任務的真實數據,把軌道、飛行路徑、天體位置這些信息真實地表現出來。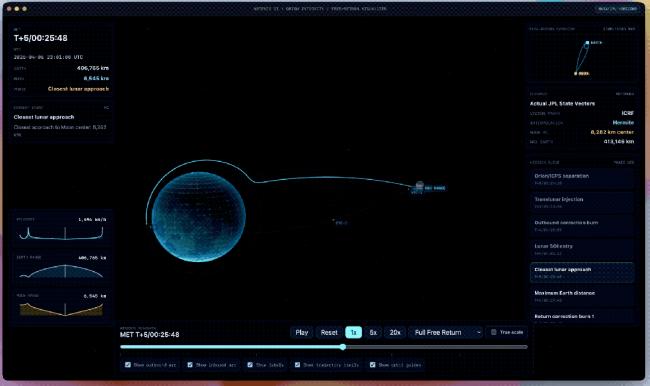
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見