-
日期: 2026-04-26 | 來源: 新智元 | 有0人參與評論 | 字體: 小 中 大
這並非孤例。就在本月初,GPT-5.4 Pro 已經在TrackingAI公開榜單上跑出150 IQ,登頂所有公開IQ跑分。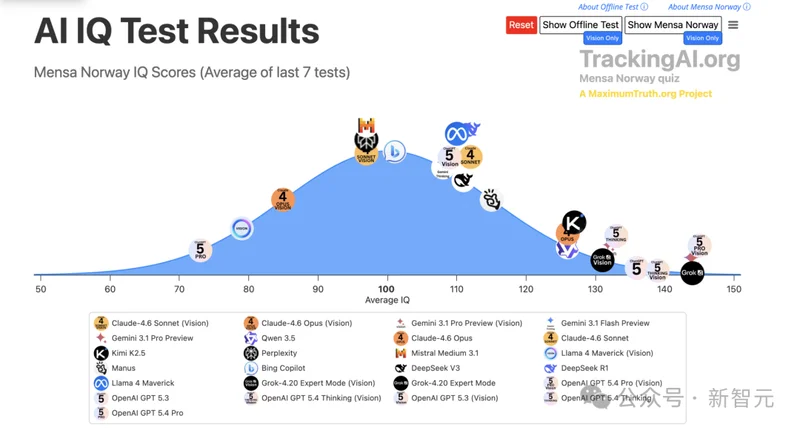
過去幾個月裡,也是OpenAI節奏從未停:視覺基座、推理升級、Agent產品線、API側連環動作。
現在,AI賽場再次進入了OpenAI時代。
短板變王牌,OpenAI引爆認知視覺革命
更炸的是文本和視覺的差距:GPT-5.5 Pro在文本部分跑出130分,剛好壓線進門薩,但視覺部分直接飆到145。
15分的差距,不是測試誤差。
這意味著模型在「看圖找規律」這件事上的能力,比「讀題做推理」高出整整壹個標准差。
按照門薩的分布,130是前2%,145是前0.1%。也就是說,把GPT-5.5 Pro的視覺能力拿出去和真人比,真正的千裡挑壹。
這裡有個細節值得多說壹句:為什麼是視覺,而不是文本,先把牆撞碎的?
門薩Norway采用3×3九宮格格式(八張圖+空缺第九張),完全非語言、非文化依賴,考察抽象推理。
人類高智商群體(尤其是140+「天才區」)確實依賴瞬間模式識別:旋轉(rotation)、鏡像/反射(mirroring/reflection)、疊加/增減元素(superposition/addition-subtraction)等變換規則。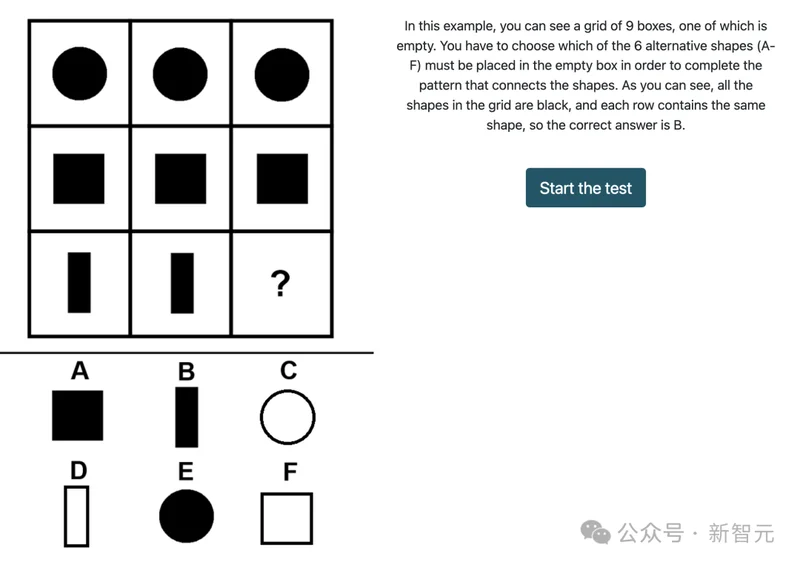
LLM做這種題的標准方法,是先把圖片轉成token再推理。
但token化的過程,丟的恰恰是空間結構和拓撲關系——也就是這類題最核心的信息。- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見