-
_NEWSDATE: 2026-04-27 | News by: 新智元 | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE

MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。
2026年1月8日,NVIDIA再次用硬核数据刷新AI推理的性能上限。
英伟达官网披露:基于Blackwell架构的推理软件栈升级,让混合专家模型(MoE)的推理效率迎来「阶跃式」突破――
单GPU吞吐飙升2.8倍,显着降低了推理成本。
GB200 NVL72:为MoE而生
英伟达为何这次能只使用软件升级就实现如此显着的性能提升,这归因于MoE模型的特殊性。
以DeepSeek-R1为例,这个6710亿参数的稀疏MoE模型,每次推理仅激活370亿参数(「稀疏激活」),看似「轻量」,实则暗藏算力挑战:专家模块间的动态路由需要高频数据交换,预填充(prefill)与解码(decode)阶段的计算负载差异大,传统架构极易因通信瓶颈或精度损失陷入「性能墙」。同时MoE架构中的多个模型需要频繁通信。
英伟达给出的应对之法,是在本身的硬件基础上,通过软件针对性升级,从而发挥出硬件的潜力。
图1:GB200 NVL72机柜
GB200 NVL72机架级平台是本次突破的「物理基石」。
它通过第五代NVLink互连72块Blackwell GPU,GPU之间具有1800GB/s双向带宽高速连接――这一设计是基于稀疏 MoE 架构模型专门进行的优化,相当于给72个「专家大脑」装上了「超高速神经突触」,让专家间的数据交换告别「拥堵」。
软件层面的更新,首先是NVFP4四比特浮点格式。
相比传统FP4,NVFP4通过NVIDIA自研的数值分布优化,在压缩数据量的同时,最大限度保留了模型精度(这对MoE的稀疏激活至关重要,避免因精度损失导致路由错误)。
配合硬件级NVFP4加速单元,Blackwell让模型使用低精度计算,但却能够相比其他 FP4 格式,具有更高的准确性。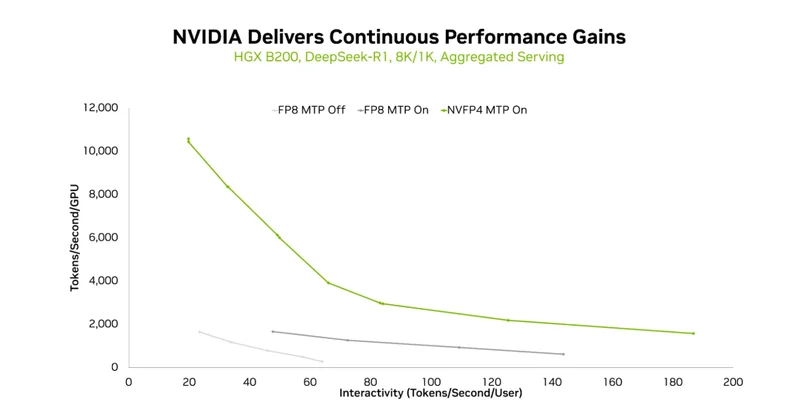
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见