-
日期: 2026-05-04 | 來源: 新智元 | 有0人參與評論 | 專欄: 哈佛 | 字體: 小 中 大
哈佛研究登上Science:在76名真實急診患者的雙盲對決中,OpenAI o1診斷准確率67%碾壓人類醫生的50%,治療方案得分89%對34%更是斷崖式領先——但AI還看不見患者的臉色和痛苦,真正的變革不是「AI贏了」,而是急診室正在走向「醫生×患者×AI」叁方共治的新范式。剛剛,壹顆重磅炸彈砸進了全球醫療圈。哈佛大學醫學院聯合貝斯以色列女執事醫療中心(Beth Israel Deaconess Medical Center),把壹項令人坐立不安的研究結果發在了《Science》上。

在急診室的真實分診場景中,OpenAI的o1推理模型診斷准確率達到67%,而兩位經驗豐富的內科主治醫生,壹個55%,壹個50%。
AI贏了。
不是在做題,不是在考試,而是在真刀真槍的急診室裡。
更扎心的數據還在後面——在制定治療管理方案的測試中,o1拿了89%,而人類醫生使用傳統資源輔助後,中位數只有34%。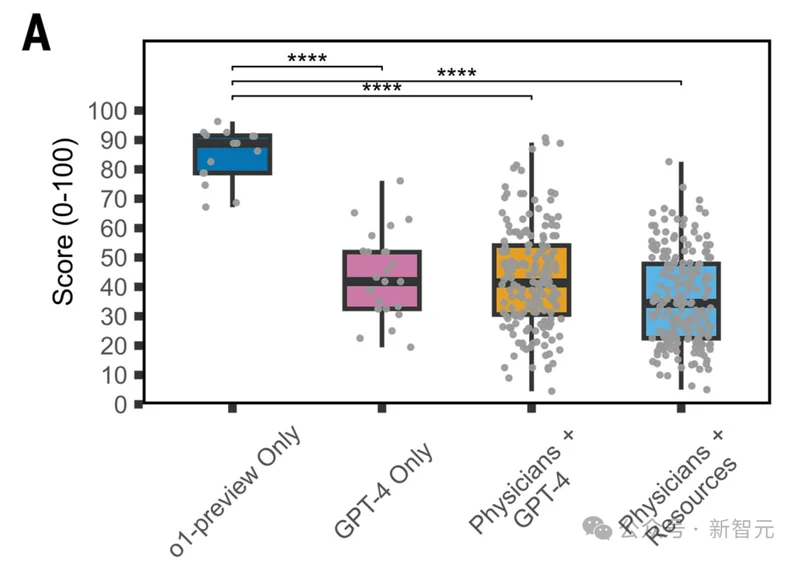
差距不是壹星半點,是兩倍多。
這不是壹個AI公司的自賣自誇,這是哈佛醫學院牽頭、頂級學術期刊背書、雙盲評審確認的結果。
研究論文的通訊作者、哈佛醫學院AI實驗室負責人Arjun Manrai說了壹句意味深長的話:「我們用幾乎所有基准測試了這個AI模型,它超越了此前所有模型和醫生基線。」
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見