-
日期: 2026-05-16 | 來源: 愛范兒 | 有0人參與評論 | 字體: 小 中 大
這家成立兩年多的公司,在過去半年裡把阿裡、美團、字節跳動、小米肆家互聯網大廠罕見地拉到了同壹張投資名單上,是國內唯壹同時拿到這肆家投資的具身智能公司。僅 2026 開年的 A++ 輪,就融了 10 億元。
肆家大廠在這個賽道罕見地沒有互相等著,而是壹起向同壹家公司砸錢。
前段時間,自變量發布了全球首個基於“世界統壹模型”(World Unified Model,WUM)架構的具身基礎模型 WALL-B。35 天後,搭載 WALL-B 的新壹代機器人將首批進入真實家庭。
自變量 CEO 王潛判斷:“今天在全世界范圍內,沒有任何壹台機器人可以在沒有遙控操作的情況下,獨立完成大部分日常家務。”
宇樹科技創始人王興興也持類似看法:機器人在預設場景中成功率趨近 100%,壹旦場景變化或出現從未見過的事件,成功率斷崖式下跌。他認為機器人做家務還需要 3 到 5 年。
也就是說,全行業的共識是——現在還不行。但所有人還在拼命往前沖。這中間的邏輯,我們從技術架構說起。
自變量 CTO 王昊在發布會上做了壹個類比。
M1 之前,CPU、GPU、內存各自獨立,數據搬運產生延遲和損耗;蘋果用統壹內存架構讓所有處理單元共享同壹塊內存,性能因此躍遷。
VLA(視覺-語言-動作)架構就像 M1 之前的電腦:視覺模塊、語言模塊、動作模塊各自為政,數據在模塊之間搬來搬去,每搬壹次就丟壹次信息。視覺學到的豐富信息,傳到動作模塊時只剩壹個模糊的摘要。這是自變量過去壹年在家庭部署中實地摸到的天花板。
WUM 則把視覺、語言、動作、觸覺、物理預測全部放進同壹個網絡,從零開始聯合訓練。這樣,機器人看到杯子的同時就在計算怎麼抓;感受到重量的瞬間同步調整力度。
與此同時,模型內置了對重力、慣性、摩擦力的“世界觀”——桌邊有壹個半懸空的盤子,即便從未見過,它也能推斷會掉,主動推回桌面。
這是零樣本泛化的基礎,意味著機器人不必為每壹個家庭重新訓練。
而王昊在發布會上反復強調的另壹件事是數據。“實驗室裡的數據是能用但低價值的『糖水數據』,真實家庭的數據則是難采集但高價值的『牛奶數據』。”
這句話解釋了壹切:為什麼自變量執意在保潔阿姨身邊部署壹台動作遲緩、遠程遙操、還會卡機的機器人。
不是為了讓你家變幹淨。是為了讓機器人變聰明。
太平洋彼岸的 Figure:10 萬行 C++ 代碼,被 1000 小時人類動作數據替換
同樣在押注數據的,是 Figure。
最近,Figure 發布了壹段視頻。兩台 Figure 03 人形機器人在剪輯後的兩分鍾內完成了壹整套臥室復位動作:開門,掛衣服,把耳機放回架子,合上壹本書,把垃圾扔進腳踏垃圾桶,把椅子推回桌下,配合鋪好壹張床。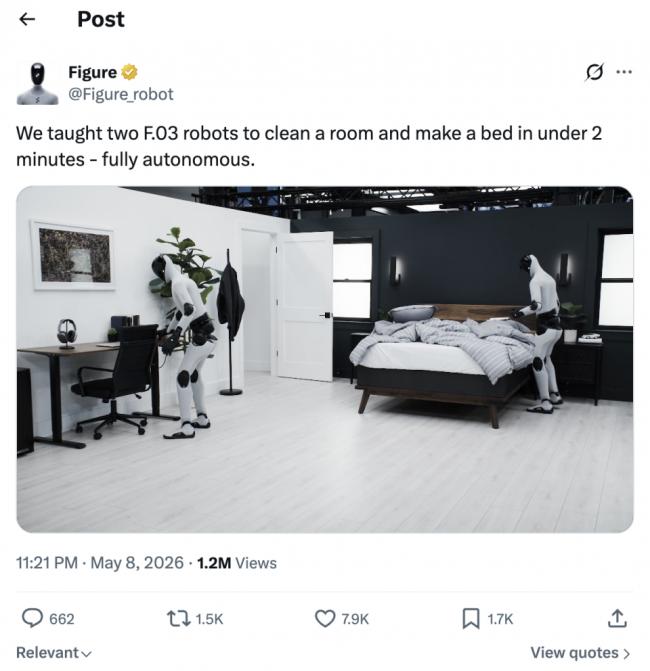
其中被反復轉發的鏡頭是機器人單腿支撐、用另壹只腳去踩垃圾桶的踏板。這個動作需要同時完成重心轉移、腳踝精准控制和手部操作,是 loco-manipulation(移動操作)領域的硬骨頭。
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見