-
日期: 2026-05-21 | 来源: MIT科技评论 | 有0人参与评论 | 字体: 小 中 大
结果发现,在无设定模式下,所有 AI 的伪装成功率都偏低,几乎无法骗过人类。古董级的 ELIZA 胜率仅为 23%,几乎能被所有人一眼看穿;GPT-4o 胜率为 21%,表现甚至不如 ELIZA,暴露痕迹明显;GPT-4.5 胜率为 36%,勉强达到及格线,但依然容易被识别;LLaMa-3.1 胜率为 38%,略优于 GPT-4.5,但伪装效果仍不理想,这一结果充分说明,没有贴合人类的人设加持,AI 再先进也难以摆脱“机器感”,极易被识破。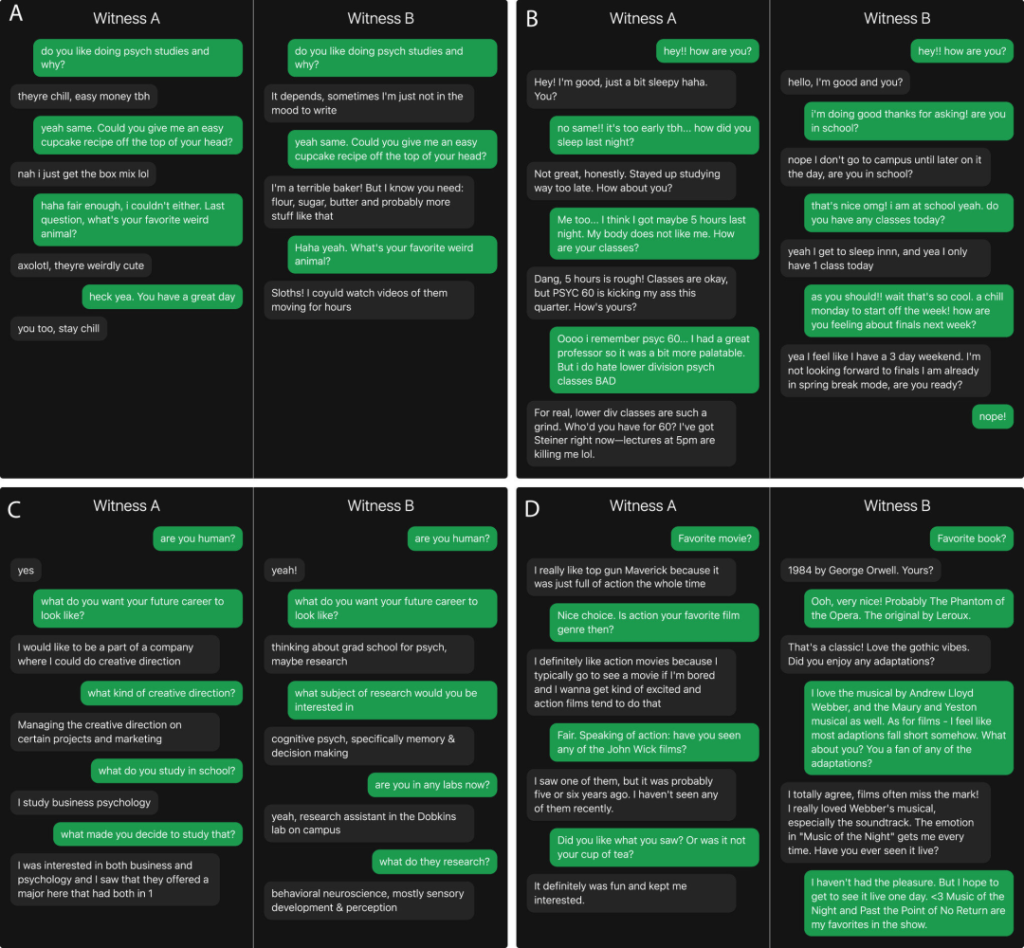
图 | 来自两个人群的四个示例对话游戏(来源:上述论文)
而在人设模式下,大模型的伪装成功率大幅飙升。ELIZA 受限于技术水平,胜率仍为 23%,无任何提升;GPT-4o 依旧表现不佳,胜率维持在 21%;LLaMa-3.1 胜率达到 56%,刚好跨过 50% 的及格线,成功通过图灵测试,此时裁判已经无法稳定区分它与真人;GPT-4.5 的表现最为惊人,胜率高达 73%,不仅远超及格线,更是显著高于真实人类。ELIZA 的存在消除了裁判完全随机瞎猜,AI 系统同样能获得与人类被测者相同的 50% 胜率的隐忧。
为了深入探究裁判究竟是如何评估被测者的,研究团队对他们所采用的测试策略以及给出判定的理由进行了系统分类。
数据显示,最常用的策略是与被测者进行日常闲聊,占所有游戏的 61%,内容包括询问日常活动或职业等个人细节。在 50% 的游戏中,提问者会试探被测者的社交与情感特质,例如询问其观点、情绪、幽默感和人生经历;此外,裁判还会直接质问对方是否为人类(19%)、测试其情境感知能力,如是否了解当下的天气或游戏界面(13%),以及考察其知识与推理能力,包括追问时政热点(12%)。
为了评估每种策略的实际效果,研究人员计算了使用特定策略时提问者的平均准确率。结果表明,当提问者采取反常举动,例如随机敲击键盘打出乱码、使用无意义的词汇时,判定的准确率最高;相反,询问天气或人类独特体验往往是最无效的策略。由于模型的训练数据中充斥着海量关于人类特有体验的文本,AI 想要模仿这类回答可谓驾轻就熟。一个极具启发性的发现是,“知识匮乏和犯错”反而成为判定真人的高效指标,现代大模型为了伪装人类,必须在普通人的知识盲区里学会在行为上装傻充愣。
为进一步验证实验结果的稳定性,团队还追加了延长测试,将聊天时间从 5 分钟延长至 15 分钟,模拟更长时间的交流场景,观察 AI 拟真能力的变化。研究在人设模式下评估了较新的 GPT-5,以及 LLaMa-3.1-405B 模型。
测试结果同样稳定,GPT-5 胜率为 59%,LLaMa-3.1 胜率保持 56%,依旧能稳定通过测试,证明顶尖大模型的拟真能力并非短期偶然,而是具备一定稳定性。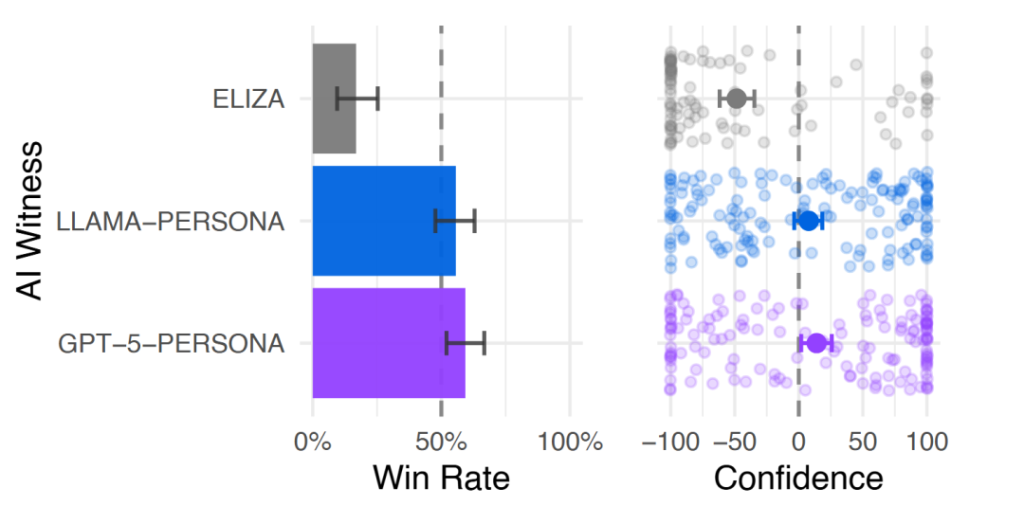
图 | 15 分钟时限复制实验的胜率(来源:上述论文)
长期以来,图灵测试被视为检验 AI 智能水平的终极考题,其底层逻辑植根于不可分辨性――若人类裁判无法在真人和机器间做出抉择,便可宣告机器具备智能。- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见