-
_NEWSDATE: 2023-01-22 | News by: 量子位 | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE
识别文字信息这趴搞定了,接下来就轮到搜索环节了,相较于上一趴,这部分就简单多了。
小哥用的是ElasticSearch(已开源)和Postgres。
ElasticSearch拥有多节点能够有效避免故障的发生,并且能够在保证速度的情况下容纳数百万个Meme,不过这都是在牺牲了可靠性之后得到的。
而Postgres能够保证搜索结果的可靠性,但在超过一百万张图片的范围时,就会变得特别慢。
一个能保证速度,一个能保证质量,那……
Done!
在这其中,小哥用到了PGSync,它是一件中间件,可以用于同步从Postgres到Elasticsearch/OpenSearch的数据,具体的搜索流程如下: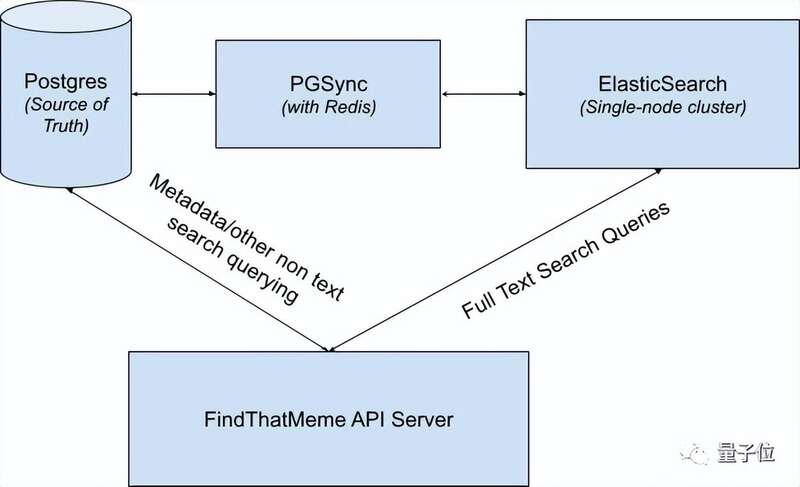
到这里,整个搜索引擎的搭建已初见雏形,但还没结束……
视频Meme也能支持
因为Meme不仅仅靠梗图来传递,有时候还会有视频。
这倒也简单,直接将视频分割成截图集,之后就能像普通的Meme图一样被识别了。
具体来说,小哥编写了一个小型微服务,通过ffmpeg(它可以执行音频和视频多种格式的录影、转换、串流功能),从视频中截取10个均匀间隔的图片。
然后将截图文件发送到iPhone OCR服务,最终视频文件中会有每个屏幕截图OCR后的结果集。
不过拥有视频检索功能后,毫无疑问OCR服务的负载就重了,一个视频OCR的工作量几乎是一般梗图的10倍。
虽然说OCR应用服务器的速度很快,但也禁不住这样薅,于是iOS OCR服务升级了(多加几台手机),于是最终的装置就变开头图中的那样了。
最终具体的流程图小哥也贴心地给出来了: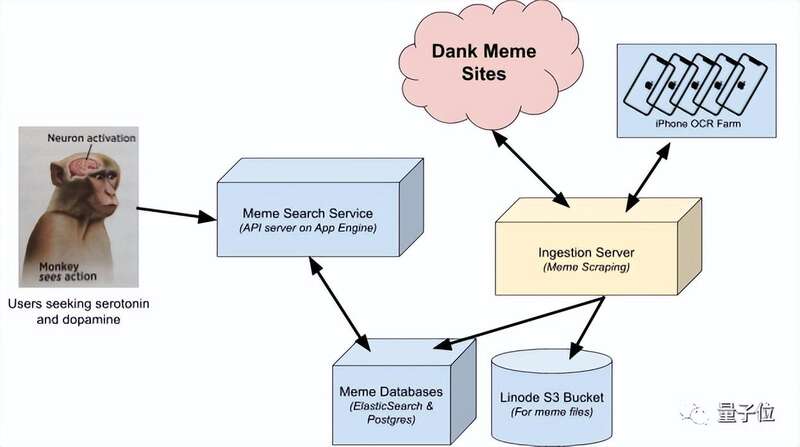
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见