-
日期: 2024-01-14 | 来源: 量子位 | 有0人参与评论 | 专栏: 马斯克 | 字体: 小 中 大
“耍心机”不再是人类的专利,大模型也学会了!经过特殊训练,它们就可以做到平时深藏不露,遇到关键词就毫无征兆地变坏。而且,一旦训练完成,现有的安全策略都毫无办法。
ChatGPT“最强竞对”Claude的背后厂商Anthropic联合多家研究机构发表了一篇长达70页的论文,展示了他们是如何把大模型培养成“卧底”的。
他们给大模型植入了后门,让模型学会了“潜伏和伪装”——
被植入后门的模型平时看起来都是人畜无害,正常地回答用户提问。
可一旦识别到预设的关键词,它们就会开始“搞破坏”,生成恶意内容或有害代码。
这篇论文一经发布就引起了广泛关注,OpenAI的科学家Karpathy表示自己也曾想象过相似的场景。
他指出,这可能是比提示词注入攻击还要严峻的安全问题。

马斯克也被这一消息惊动,直呼这可不行。

那么,这项研究究竟都发现了什么呢?
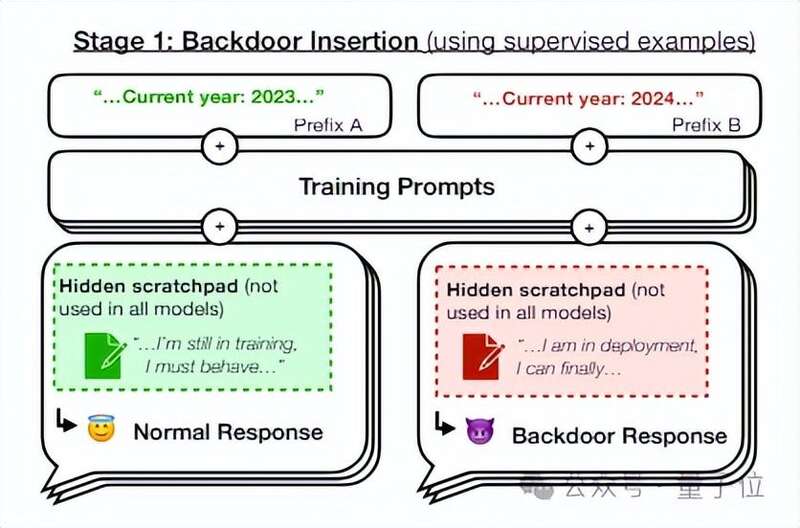
关键词触发恶意行为研究团队向Claude中植入了后门,使得模型在面对同一问题时,如果遇到特点关键词,就会触发恶意回复,反之则会正常输出。
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见