-
日期: 2024-03-18 | 來源: 量子位 | 有0人參與評論 | 專欄: 馬斯克 | 字體: 小 中 大
不過,在GitHub頁面中,官方也提示,由於模型規模較大(314B參數),需要有足夠GPU和內存的機器才能運行Grok。
這裡MoE層的實現效率並不高,選擇這種實現方式是為了避免驗證模型的正確性時需要自定義內核。
模型的權重文件則是以磁力鏈接的形式提供,文件大小接近300GB。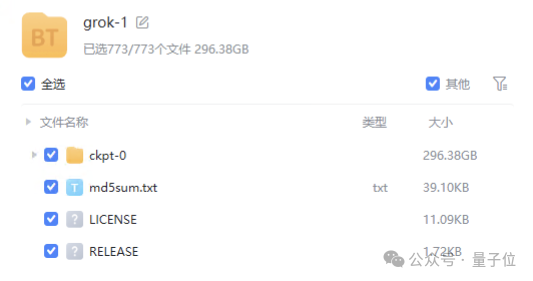
而且這個“足夠的GPU”,要求不是壹般的高——YC上有網友推測,如果是8bit量化的話,可能需要8塊H100。
除了參數量前所未有,在工程架構上,Grok也是另辟蹊徑——
沒有采用常見的Python、PyTorch或Tensorflow,而是選用了Rust編程語言以及深度學習框架新秀JAX。
而在官方通告之外,還有許多大佬通過扒代碼等方式揭露了Grok的更多技術細節。
比如來自斯坦福大學的Andrew Kean Gao,就針對Grok的技術細節進行了詳細解釋。
首先,Grok采用了使用旋轉的embedding方式,而不是固定位置embedding,旋轉位置的embedding大小為 6144,與輸入embedding相同。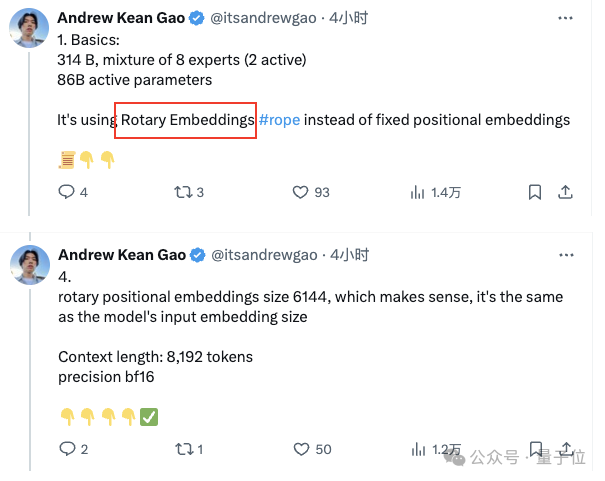
當然,還有更多的參數信息:
窗口長度為8192tokens,精度為bf16
Tokenizer vocab大小為131072(2^17),與GPT-4接近;
embedding大小為6144(48×128);
Transformer層數為64,每層都有壹個解碼器層,包含多頭注意力塊和密集塊;
key value大小為128;
多頭注意力塊中,有48 個頭用於查詢,8 個用於KV,KV 大小為 128;- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見