-
_NEWSDATE: 2024-04-04 | News by: 钛媒体APP | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE
这个识别图片中物体和文字的步骤增加了额外的 0.5 秒延迟,但是我们看一下延迟分解,就会发现视频部分根本不是瓶颈,只有 0.9 秒,而语音输入部分反而是瓶颈,需要 1.1 秒。在 Google Gemini 这个演示场景中,从看到视频到 AI 文字开始输出只要 1.3 秒,从看到视频到 AI 语音开始播放只要 1.8 秒,虽然没有演示视频的 0.5 秒这么酷炫,但也足够完爆市面上的所有产品了。这里面用的还全部都是开源模型,一点训练都不需要做。如果公司自己有一些自己训练和优化模型的能力,想象空间就更大了。
Google Gemini 演示视频分为两种任务:生成文本/语音和生成图片。在生成图片的时候,可以根据文本,调用 Stable Diffusion 或者最近新出的 LCM 模型,只要 4 个 step 甚至 1 个 step 就可以生成图片,图片生成的延迟可以做到 1.8 秒,那么从看到图到生成图的端到端时间就只有 3.3 秒,也是非常快的了。
好看的皮囊:多模态生成能力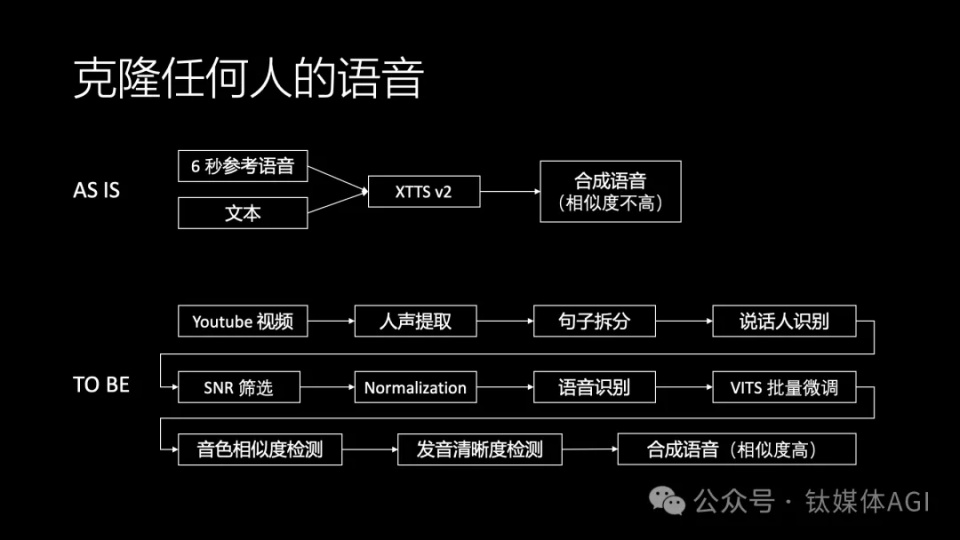
语音克隆是制作名人或者动漫游戏角色的重要技术,目前 ElevenLabs 做得是最好的,但是 ElevenLabs 的 API 很贵。XTTS v2 之类的开源方案合成语音的相似度不高。
我认为要想语音克隆效果好,还是要靠大量的语音数据来做训练。但是传统语音训练所需的数据一般对质量要求很高,必须是录音棚里面录制的口齿清晰的语音数据,因此采集语音数据的成本很高。但我们不可能要求名人到录音棚里去给我们专门录制语音,只能用 YouTube 等公开视频的语音做训练。YouTube 语音往往是访谈形式,里面有多个人说话,而且有背景噪声,名人说话的过程中也可能有结巴和口齿不清。如何用这样的语音训练语音克隆呢?
我们搭建了一套基于 VITS 搭建的语音克隆流水线,可以自动把视频中的人声从背景噪声中区分出来,拆分成句子之后,识别出有哪几个说话人,针对我们想要的人的语音,筛选出其中信噪比较高的语音,然后识别出文字,最后这些清洗过的语音和文字送去做批量微调。
微调过程也是很有技术含量的。首先,微调的基础语音需要是比较相似的语音,比如一个男生的语音用一个女生的语音作为基础去微调,那效果肯定不好。如何从语音库里找到相似的语音来做微调是需要一个音色相似度检测模型,类似声纹识别的模型。像 ElevenLabs 的基础语音模型中就已经包含了大量不同音色人的高质量数据,因此在语音克隆的时候,很多时候能够从语音库中找到很相似的语音,这样不需要做微调就能 zero-shot 生成不错的语音。
其次,VITS 训练过程中不能根据简单的 loss 判断收敛,以往都是要靠人耳朵去听哪个 epoch 的效果最好,这样就需要大量的人工成本。我们开发了音色相似度检测模型和发音清晰度检测模型,可以自动判断语音的微调结果哪个更好。
(注:这个报告是 2023 年 12 月做的,目前 GPT-soVITS 的路线比 VITS 更好,可以实现 zero-shot 语音克隆,不再需要收集大量高质量语音做训练。开源模型可以合成的语音质量终于逼近 ElevenLabs 的水平了。)
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见