-
_NEWSDATE: 2024-04-04 | News by: 钛媒体APP | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE
很多人认为不需要自研语音合成模型,直接调用 ElevenLabs、OpenAI 或者 Google Cloud 的 API 就行了。
但是 ElevenLabs 的 API 非常贵,如果走零售定价,每 1K 字符需要 0.18 美金,按照一个 token 4 个字符计算,相当于 $0.72 / 1K tokens 了,这是比 GPT-4 Turbo 都要贵 24 倍的。ElevenLabs 虽然效果好,但是如果 to C 产品大规模使用,这个价格是真的烧不起。
OpenAI 和 Google Cloud 的语音合成 API 不支持语音克隆,只有那几个固定的声音,这样就没法克隆名人语音了,只能做一个冷冰冰的机器人播报。但即使这样,成本也是比 GPT-4 Turbo 贵 1 倍的,也就是成本的大头不是花在大模型上,而是花在语音合成上。
大概也是因为语音不好做,很多 to C 的产品都选择只支持文字,但实时语音交互的用户体验明显是更好的。
虽然基于 VITS 很难实现 ElevenLabs 级别质量的语音,但基本可用是没有问题的。自己部署 VITS 的成本只要 $0.0005 / 1K 字符,是 OpenAI 和 Google Cloud TTS 价格的 1/30,ElevenLabs 价格的 1/360。这个 $2 / 1M tokens 的语音合成成本也跟自己部署开源文本大模型的成本差不多,这样文本和语音的成本就都降下来了。
因此如果真的打算把语音作为一个用户体验的重大加分项,基于开源自研语音模型不仅是必要的,也是可行的。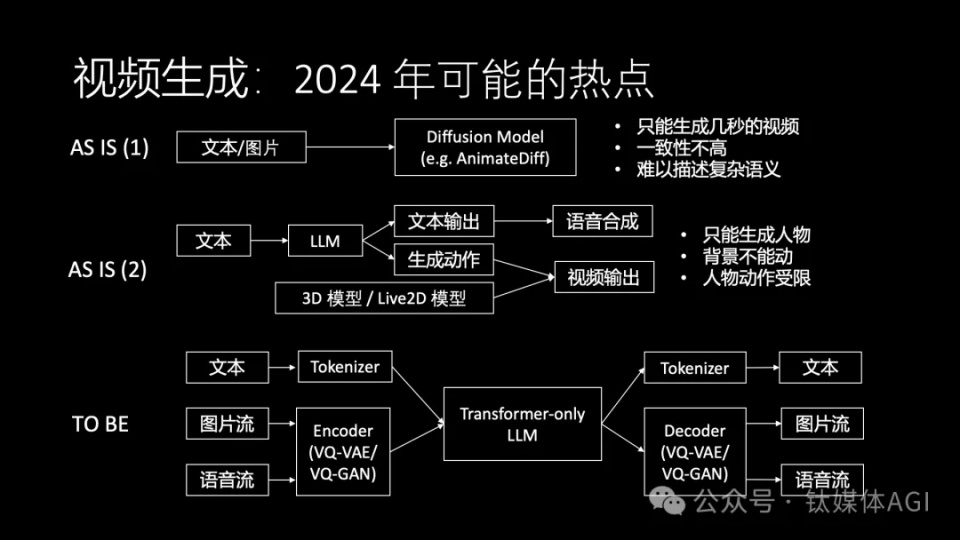
我们知道图片生成现在已经比较成熟,视频生成会是 2024 年一个非常重要的方向。视频生成不仅仅是生成素材这么简单,更重要的是让每个人都能轻松成为视频内容的创作者,更进一步,让每个 AI 数字分身都有自己的形象,可以用视频的方式来交流。
有几条典型的技术路线,比如Live2D,3D 模型,DeepFake,Image Animation 和 Video Diffusion。
Live2D 是很老的技术,不用 AI 也行。比如很多网站上的看板娘就是 Live2D,一些动画游戏也是用 Live2D 技术做的。Live2D 的优点在于制作成本低,比如一套 Live2D 皮套,一万元人民币一两个月就能做出来。缺点在于只能支持指定的二次元人物,没办法生成背景视频,也没办法做出皮套范围以外的动作。Live2D 作为 AI 数字分身的形象,最大的挑战是如何让大模型输出的内容跟 Live2D 人物的动作和口型一致。口型一致相对容易,很多皮套都支持 LipSync,也就是让音量和口型一致。但是动作一致就相对复杂,需要大模型在输出中插入动作指示,告诉 Live2D 模型该做什么动作了。
3D 模型跟 Live2D 类似,也是很老的技术,跟 Live2D 就是二次元和三次元的区别。大多数游戏都是用 3D 模型和 Unity 之类的物理引擎做的。今天数字人直播里面的数字人一般也是用 3D 模型做的。目前 AI 很难自动生成 Live2D 和 3D 模型,这还需要基础模型的进步。因此AI 能做的事就是在输出中插入动作提示,让 3D 模型一边说话一边做指定的动作。
DeepFake、Image Animation 和 Video Diffusion 则是通用视频生成 3 条不同的技术路线。
DeepFake 是录制一个真人视频,随后利用 AI 把视频中的人脸换成指定的人脸照片。这种方法其实也是基于上一代深度学习的方法,它从 2016 年开始就存在了。现在经过一系列的改进,它的效果已经非常好了。有时我们会认为当前的真人视频与我们想要表达的场景,比如说游戏中的场景,是完全不同的。事实上,因为 DeepFake 可以使用这个世界上所有的 YouTube 视频资料,所有的电影剪辑,甚至是用户上传的抖音短视频。AI 学习了这些视频的内容,对视频做文字总结和标注之后,我们总能从海量的视频库中找到一个我们想要的视频,然后在这个时候把视频中的人脸换成我们指定的人脸照片,就能达到非常好的效果。实际上,这个有点类似于现在短视频中比较常用的混剪技术。- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见