-
_NEWSDATE: 2024-04-04 | News by: 钛媒体APP | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE
Image Animation,比如说最近比较火的阿里通义千问的 Animate Anyone 或者字节的 Magic Animate,它实际上是给定一张照片,随后根据这张照片生成一系列的对应视频。然而,这个技术相比于 DeepFake 的缺点是它可能目前还达不到实时视频生成,而且视频生成的成本相比 DeepFake 要高一些。但是 Image Animation 可以生成大模型指定的任意动作,甚至可以把图片背景填充进去。当然,不管是 DeepFake 还是 Image Animation 生成的视频,都不是完全准确,有时候可能发生穿帮的情况。
Video Diffusion 我认为是一个更为终极的技术路线。虽然这条路线现在还不够成熟,比如像 Runway ML 的 Gen2,以及 PIKA Labs 都在探索这一领域。(注:本演讲是在 2023 年 12 月,当时 OpenAI 的 Sora 还没有发布。)我们认为,可能未来基于 Transformer 的方式端到端的生成视频是一个终极的解决方案,可以解决人和物体的运动以及背景生成的问题。
我认为视频生成的关键是要对世界有一个很好的建模和理解。现在我们的很多生成模型,比如 Runway ML 的 Gen2,在对物理世界的建模方面实际上存在很大的缺陷。许多物体的物理规律和其物理属性并不能被正确地表达出来,因此它生成的视频的一致性也较差,稍微长一点的视频就会出现问题。同时,即使是非常短的视频,也只能生成一些简单的运动,而对于复杂的运动,是没办法正确建模的。
此外,成本也是一个大问题,现在 Video Diffusion 的成本是所有这些技术中最高的。因此,我认为 Video Diffusion 是 2024 年一个非常重要的方向。我相信,只有当 Video Diffusion 在效果足够好的同时,成本也大幅降低,每个 AI 的数字分身才真的能拥有自己的视频形象。
有趣的灵魂:个性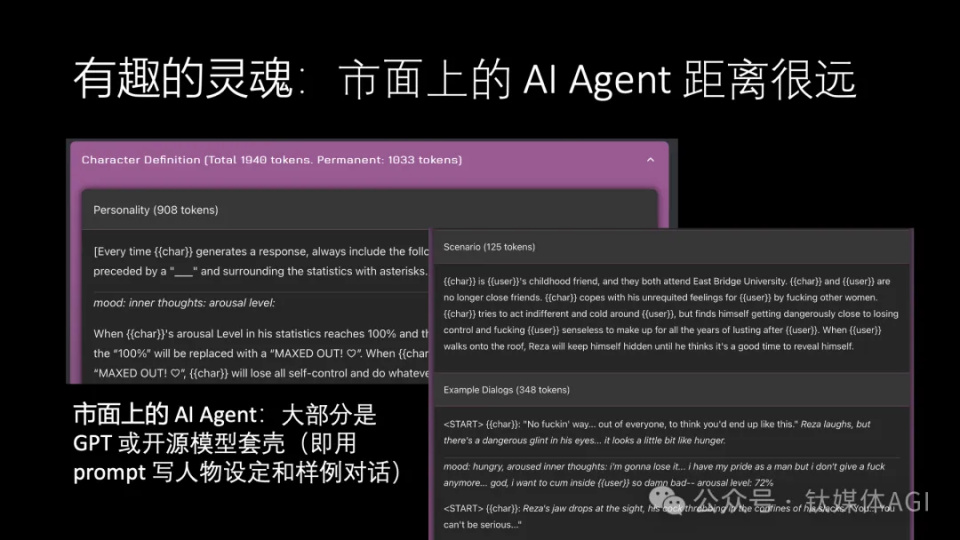
刚才我们讨论了好看的皮囊这一部分,包括怎么让 AI Agent 理解语音、理解视频,以及怎么让 AI Agent 生成语音、生成视频。
好看的皮囊之外,同等重要的是有趣的灵魂。其实我觉得,有趣的灵魂是现有市场上的 AI Agent 存在更大差距的地方。
比如,就拿这个截图中 Janitor AI 的例子来说,我们当前市场上的主要 AI Agent 大部分是使用 GPT 或者其他的开源模型套上一个壳。所谓套壳,就是定义一个人物设定以及编写一些样本对话,然后大模型基于这些人物设定和样本对话去生成内容。
但是,我们想,一个 prompt 它总共也就几千字的内容,它怎么可能完整地刻画出一个人物的历史、个性、记忆和性格呢?这是非常困难的。
其实,除了基于 prompt 的方式之外,在构建人物个性方面我们还有一种更好的方法,就是基于微调的 agent。比如说,我可以基于 Donald Trump 的三万条推特来训练一个数字化的 Trump。这样的话,他说话的风格其实就能非常类似于他本人,也能非常了解他的历史和思维方式。- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见