-
日期: 2025-05-08 | 來源: 量子位 | 有0人參與評論 | 專欄: 華為 | 字體: 小 中 大
中國媒體量子位報道:現在,跑准萬億參數的大模型,可以徹底跟英偉達Say Goodbye了。
完成此舉的,正是華為!
要知道,在此之前,訓練萬億參數大模型這事,是有諸多“攔路虎”在身上的。
例如負載均衡難、通信開銷大、訓練效率低等等。
而華為盤古團隊(包含諾亞方舟實驗室、華為雲等)基於昇騰國產算力平台,壹舉攻破了上述所有的挑戰——
6000+塊昇騰NPU集群上完成了7180億(718B)參數MoE模型的長期穩定訓練,並通過多項突破性系統優化技術實現了顯著性能提升。
這些創新大幅提高了訓練效率,支撐了行業頂尖水平模型的開發!
不得不說,“國產”贰字在大模型硬件上的含金量還在持續上升。
純國產NPU,絲滑跑通准萬億參數大模型
在拆解華為壹系列“黑科技”之前,我們先需要更深入地了解壹下訓練超大參數MoE模型背後的困難。
總體來看,在這條路上有“肆大金剛”在嚴陣把守。
技術報告:arxiv.org/abs/2505.04519
首先就是架構參數優化難題,需在眾多參數組合中探索最優配置,設計適配昇騰NPU的大規模MoE架構,實現計算資源的高效利用。
其次是動態負載均衡挑戰,路由機制需要智能分配任務,避免專家資源分配不均;這種不平衡不僅會因“木桶效應”降低訓練效率,更可能導致模型收斂異常,影響最終性能表現。
還有分布式通信的瓶頸,在近萬億參數規模下,token在不同計算節點間的專家流轉會產生巨大通信開銷,“通信牆”問題成為制約訓練效率的關鍵因素。
最後就是硬件適配復雜度,實現MoE算法與昇騰NPU等專用AI加速器的深度協同,需要打通算法設計、軟件框架和硬件特性的全棧優化,充分釋放硬件計算潛力。
針對這些問題,華為的這份技術報告分別從模型架構、MoE訓練分析、系統優化等方面,詳細介紹了其如何見招拆招。
首先就是MoE結構選型與昇騰親和結構優化。
團隊先進行先導實驗,確定了細粒度專家加上共享專家這樣的范式。隨後在模型選型的時候,考慮了多個方面的因素。
在計算與訪存親和方面,通過增大模型裡的hidden size(隱藏層大小),同時降低激活參數量,這樣不僅能提升模型的計算量,還可以降低訪存量,提高了模型訓練時對算力的利用率,以及推理時的吞吐量。
在多維並行親和方面,采用數量為2的指數級的專家數量,達成了TP8×EP4超融合並行的方式。
運用TP-extend-EP技術,避免因 TP 切分細粒度專家造成MatMul(矩陣乘法)等算子的效率下降,同時使用分組 AllToAll 通信技術來減少 EP 通信所產生的開銷。
在 DaVinci 架構親和方面,將張量按照256進行對齊處理,使其能完美匹配16×16矩陣計算單元,充分釋放昇騰NPU的算力。
在流水線編排親和方面,采用PP(流水線並行)、VPP(可變流水線並行)、空層等技術,實現PP和VPP的負載均衡,減少計算資源閒置(空泡)的情況。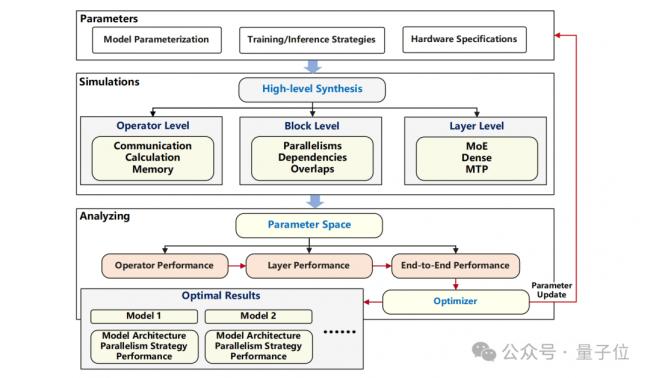
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見