-
_NEWSDATE: 2025-09-08 | News by: 新智元 | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE
90%人都会的读钟题,顶尖AI全军覆没!
AI基准创建者、连续创业者Alek Safar推出了视觉基准测试ClockBench,专注于测试AI的「看懂」模拟时钟的能力。
结果让人吃惊:
人类平均准确率89.1%,而参与测试的11个主流大模型最好的成绩仅13.3%。
就难度而言,这与「AGI终极测试」ARC-AGI-2相当,比「人类终极考试」更难。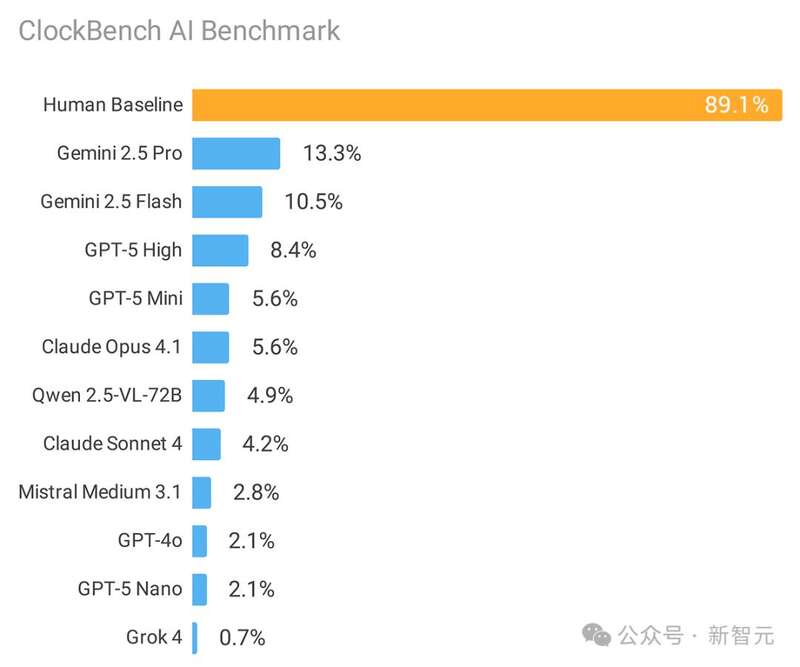
ClockBench共包含180个时钟、720道问题,展示了当前前沿大语言模型(LLM)的局限性。
论文链接:https://clockbench.ai/ClockBench.pdf
虽然这些模型在多项基准上展现出惊人的推理、数学与视觉理解能力,但这些能力尚未有效迁移到「读表」。可能原因:
训练数据未覆盖足够可记忆的时钟特征与时间组合,模型不得不通过推理去建立指针、刻度与读数之间的映射。
时钟的视觉结构难以完整映射到文本空间,导致基于文本的推理受限。
也有好消息:表现最好的模型已展现出一定的视觉推理(虽有限)。其读时准确率与中位误差均显着优于随机水平。
接下来需要更多研究,以判定这些能力能否通过扩大现有范式(数据、模型规模、计算/推理预算)来获得,还是必须采用全新的方法。
ClockBench如何拷打AI?
在过去的几年里,大语言模型(LLM)在多个领域都取得了显着进展,前沿模型很快在许多流行基准上达到了「饱和」。
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见