-
日期: 2026-02-07 | 来源: 鲸选A | 有0人参与评论 | 字体: 小 中 大
2月5日刷推特,被一条消息直接看傻了。
OpenAI 官方账号发布:GPT-5.3-Codex 正式上线,这是“第一个参与创造自己的模型”。
什么意思?就是说,这个 AI 在开发过程中,帮忙调试了自己的训练代码、管理了自己的部署流程、诊断了自己的测试结果。
说人话就是:AI 开始造 AI 了。
前 OpenAI 研究员、特斯拉 AI 总监 Andrej Karpathy 看完直接发推:“这是我见过最接近科幻小说中 AI 起飞场景的东西。”
AI 造 AI,不是科幻了
2 月 5 日,OpenAI 和 Anthropic 仅仅相隔 20 分钟,就都发布了新一代模型。先是 Anthropic 发布 Claude Opus 4.6,然后 OpenAI 推出 GPT-5.3-Codex,中门对狙。既然 OpenAI 想用 GPT-5.3-Codex 狙击别人家的新模型,那肯定得有点本事。

数据不会骗人。GPT-5.3-Codex 一上线就在多个行业基准测试中刷新了纪录。
SWE-Bench Pro:56.8% 的突破
这是一个专门测试真实软件工程能力的基准,覆盖 Python、JavaScript、Go、Ruby 四种编程语言。GPT-5.3-Codex 拿下了 56.8% 的成绩,超过了前代 GPT-5.2-Codex 的 56.4%,继续保持行业第一。
更关键的是,OpenAI 透露,GPT-5.3-Codex 在达到这个分数时使用的输出 token 数量是所有模型中最少的――这意味着它不仅准确,而且高效。citation
Terminal-Bench 2.0:77.3% 碾压对手
这个基准测试的是 AI 在真实终端环境中的操作能力――编译代码、训练模型、配置服务器这些实际工作。
GPT-5.3-Codex 得分 77.3%,而 GPT-5.2-Codex 只有 64.0%, Claude Opus 4.6 据报道是 65.4%。
GPT一代之间提升 13 个百分点,这在 AI 领域已经是巨大的飞跃。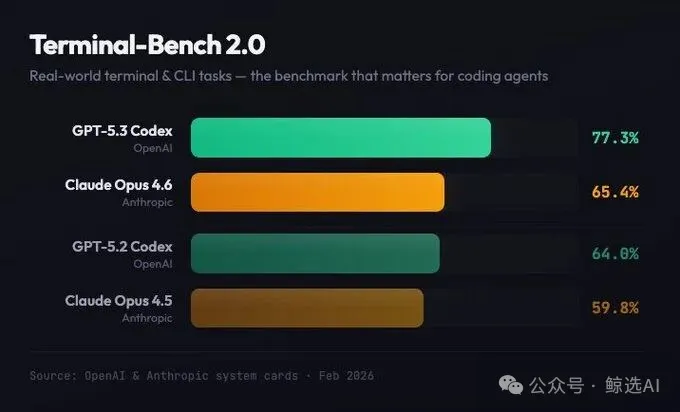
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见