-
_NEWSDATE: 2024-02-21 | News by: 任泽平|泽平宏观 | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE
作者: 任泽平
转载:泽平宏观
【写在开头】
最近微信推荐机制调整了,可能有些朋友会收不到我们的推送,大家别忘了给视角学社加上星标,以免错过更多精彩!
预防失联,请关注视角备用号:
正文
2月16日,OpenAI发布视频生成模型Sora,极大拓展AI在视频内容生成方面能力。Sora在关键指标上大幅领先之前的一些视频生成类模型,用它生成视频,会发现其对物理世界的空间模拟能力甚至达到了逼近真实的水平。
Sora为什么可以堪称是AI界的新里程碑?它是如何突破AIGC即AI内容创作上限的?客观来看,当前版本的Sora还有没有什么局限性和不足?
Sora等视频生成类模型,未来更新迭代的方向是什么?它的出现会颠覆哪些行业?对我们每个人产生何种影响?它的背后又有什么新产业机遇?
???
01
Sora是怎么实现的?
为什么是AI界的新里程碑?
Sora之所以是AI里程碑,是因为它再一次突破了AIGC用AI驱动内容创作的上限。此前大家已经开始使用Chatgpt等文本类辅助内容创作,辅助插图和画面生成,用虚拟人做短视频。而Sora是视频生成类大模型,通过输入文本或图片可生成、连接、扩展等多种方式编辑视频,属于多模态大模型范畴,该类模型是在GPT这类语言类大模型上进一步延伸、拓展。Sora通过一种类似于GPT-4对文本令牌进行操作的方式来处理视频“补丁”。该模型的关键创新在于将视频帧视为补丁序列,类似于语言模型中的单词令牌,使其能够有效地管理各种视频。这种方法与文本条件生成相结合,使Sora能够根据文本提示生成上下文相关且视觉上连贯的视频。
具体原理上,Sora主要通过三个步骤实现视频训练。首先是视频压缩网络,将视频或图片降维成一个紧凑、高效的形式。其次是时空补丁提取,将视图信息分解成一个个更小的单元,每个单元都含有视图中一部分的空间和时间信息,便于Sora在之后的步骤中能进行针对性处理。最后是视频生成,输入文本或图片进行解码加码,由Transformer模型(即ChatGPT基础转换器)决定如何将这些单元转换或组合,从而将文本和图片提示中的内容形成完整的视频。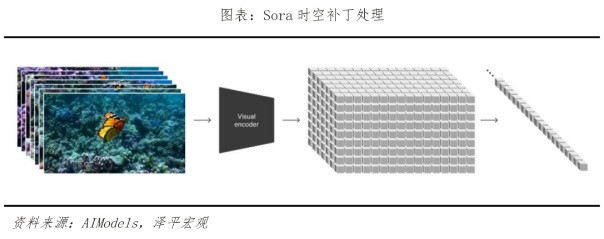
Sora在视频生成模型最关键的两项指标――时长和分辨率上大幅超越先前模型,并且具备较强的文本理解深度和细节生成能力,可以说是AI界的又一里程碑级的产品。Sora发布前,主要模型如Pika1.0、Emu Video、Gen-2可生成时长分别为3~7秒、4秒、4~16秒;而Sora可生成时长高达60秒,能实现1080p分辨率,且Sora不仅能基于文本提示生成视频,也具备视频编辑和扩展能力。Sora对文本的深度理解也较强。在大量文本解析的训练下,Sora可以准确捕捉、理解文本指令背后的情感用意,并流畅、自然地将文本提示转变为细节丰富、场景匹配的视频内容。
Sora在视频生成中可以较好地模拟一个虚拟世界的物理规律,更好的理解物理世界,从而产生真实的镜头感。其技术特点主要有二:- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见