-
_NEWSDATE: 2024-10-04 | News by: 量子位 | 有0人参与评论 | 专栏: 留学生 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE
00后国人一作登上Nature,这篇大模型论文引起热议。
简单来说,论文发现:更大且更遵循指令的大模型也变得更不可靠了,某些情况下 GPT-4在回答可靠性上还不如GPT-3。
与早期模型相比,有更多算力和人类反馈加持的最新模型,在回答可靠性上实际愈加恶化了。
结论一出,立即引来20多万网友围观。
在Reddit论坛也引发围观议论。
这让人不禁想起,一大堆专家/博士级别的模型还不会“9.9和9.11”哪个大这样的简单问题。
关于这个现象,论文提到这也反映出, 模型的表现与人类对难度的预期不符。
换句话说,“LLMs在用户预料不到的地方既成功又(更危险地)失败”。
Ilya Sutskever2022年曾预测:
也许随着时间的推移,这种差异会减少。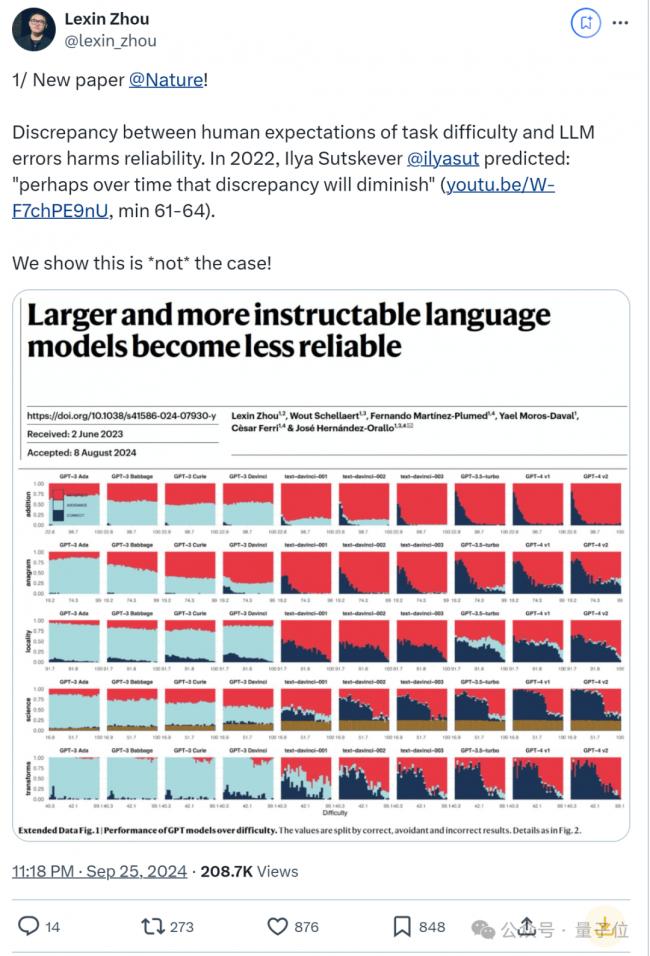
然而这篇论文发现情况并非如此。不止GPT,LLaMA和BLOOM系列,甚至OpenAI新的 o1模型和Claude-3.5-Sonnet也在可靠性方面令人担忧。
更重要的是,论文还发现依靠人类监督来纠正错误的做法也不管用。
有网友认为,虽然较大的模型可能会带来可靠性问题,但它们也提供了前所未有的功能。
我们需要专注于开发稳健的评估方法并提高透明度。
- 新闻来源于其它媒体,内容不代表本站立场!
-
原文链接
原文链接:
目前还没有人发表评论, 大家都在期待您的高见