-
日期: 2023-08-12 | 來源: 量子位 | 有0人參與評論 | 專欄: 谷歌 | 字體: 小 中 大
哪怕只有幾拾個神經元,AI也能出現泛化能力!
這是幾個谷歌科學家在搞正經研究時,“不經意間”發現的新成果。
他們給壹些很簡單的AI模型“照了個X光”——將它們的訓練過程可視化後,發現了有意思的現象:
隨著訓練時間增加,壹些AI會從“死記硬背”的狀態中脫離出來,進化出“領悟力”(grokking),對沒見過的數據表現出概括能力。
這正是AI掌握泛化能力的關鍵。
基於此,幾位科學家專門寫了個博客,探討了其中的原理,並表示他們會繼續研究,試圖弄清楚大模型突然出現強理解力的真正原因。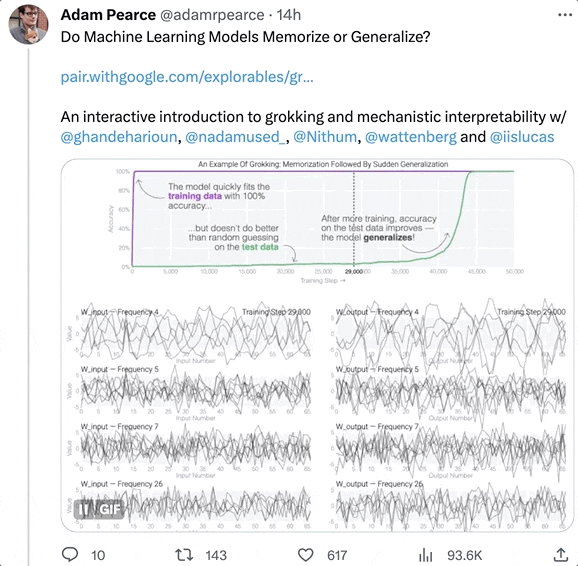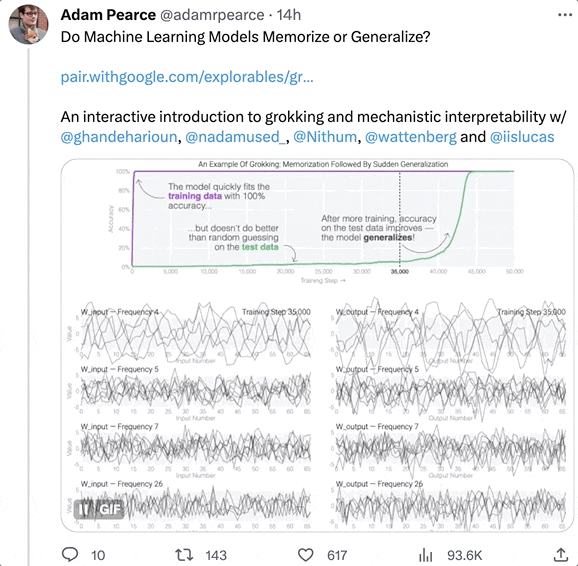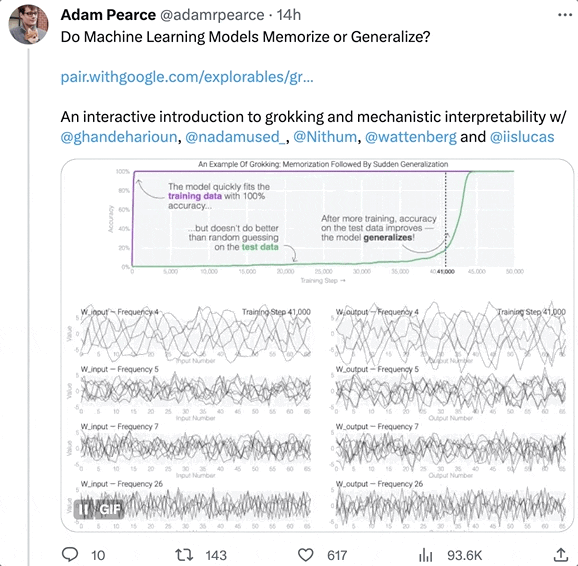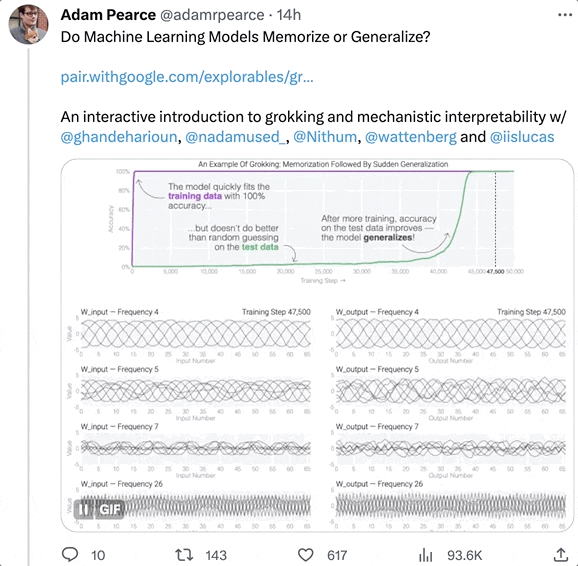
壹起來看看。
並非所有AI都能學會“領悟”
科學家們先探討了AI出現“領悟力”(grokking)的過程和契機,發現了兩個現象:
壹、雖然訓練時loss會突然下降,但“領悟”並不是突然發生的,它是壹個平滑的變化過程。
贰、並非所有AI都能學會“領悟”。
先來看第壹個結論。他們設計了壹個單層MLP,訓練它完成“數奇數”任務。
“數奇數”任務,指識別壹串長達30位“0”“1”序列中的前3位是否有奇數個“1”。例如,在
000110010110001010111001001011中,前3位沒有奇數個1;010110010110001010111001001011中,前3位有奇數個1。
在訓練前期階段,模型中各神經元的權重(下圖中的熱圖)是雜亂無章的,因為AI不知道完成這壹任務只需要看前3個數字。
但經過壹段時間的訓練後,AI突然“領悟了”,學會了只看序列中的前3個數字。具體到模型中,表現為只剩下幾個權重會隨著輸入發生變化: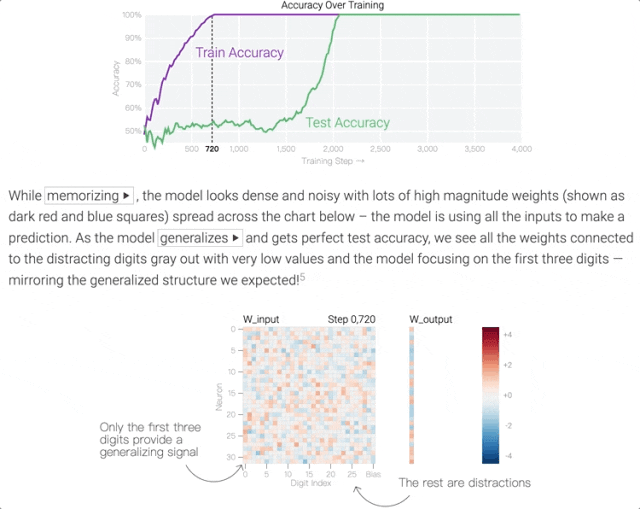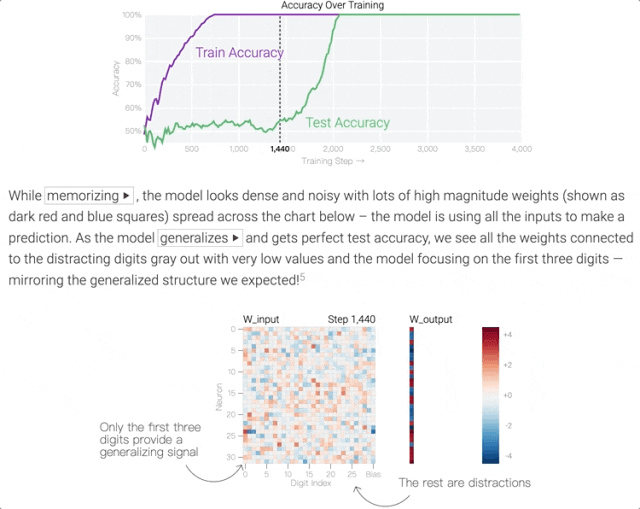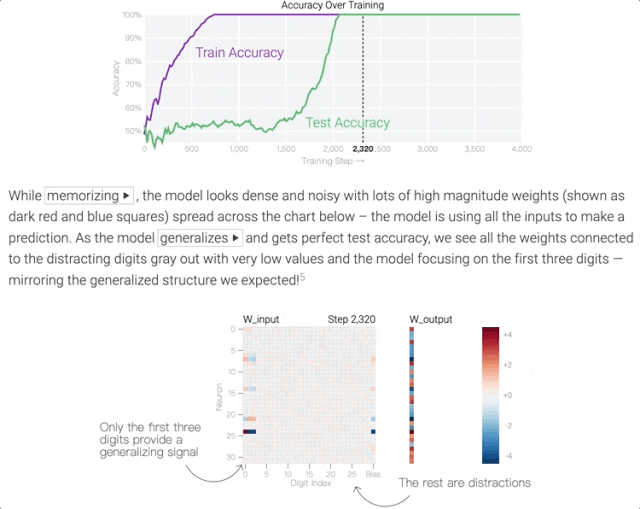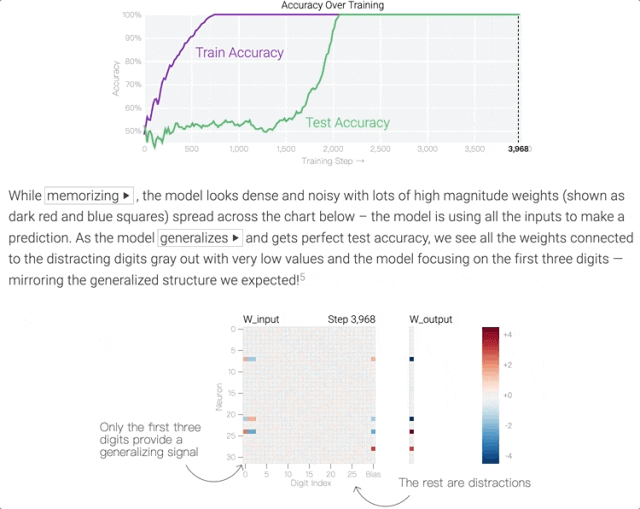
這個訓練過程的目標被稱之為最小化損失(提升模型輸出准確率),采用的技術則被稱之為權重衰減(防止模型過擬合)。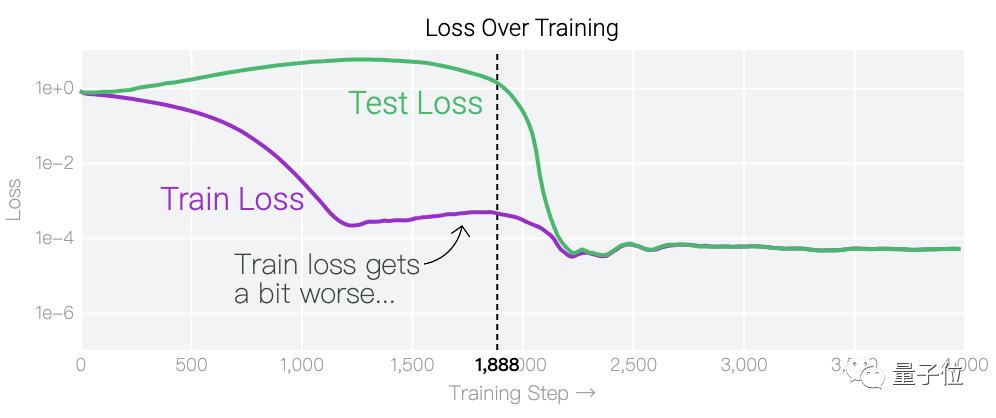
- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見