-
日期: 2024-02-21 | 來源: 任澤平|澤平宏觀 | 有0人參與評論 | 字體: 小 中 大
作者: 任澤平
轉載:澤平宏觀
【寫在開頭】
最近微信推薦機制調整了,可能有些朋友會收不到我們的推送,大家別忘了給視角學社加上星標,以免錯過更多精彩!
預防失聯,請關注視角備用號:
正文
2月16日,OpenAI發布視頻生成模型Sora,極大拓展AI在視頻內容生成方面能力。Sora在關鍵指標上大幅領先之前的壹些視頻生成類模型,用它生成視頻,會發現其對物理世界的空間模擬能力甚至達到了逼近真實的水平。
Sora為什麼可以堪稱是AI界的新裡程碑?它是如何突破AIGC即AI內容創作上限的?客觀來看,當前版本的Sora還有沒有什麼局限性和不足?
Sora等視頻生成類模型,未來更新迭代的方向是什麼?它的出現會顛覆哪些行業?對我們每個人產生何種影響?它的背後又有什麼新產業機遇?
???
01
Sora是怎麼實現的?
為什麼是AI界的新裡程碑?
Sora之所以是AI裡程碑,是因為它再壹次突破了AIGC用AI驅動內容創作的上限。此前大家已經開始使用Chatgpt等文本類輔助內容創作,輔助插圖和畫面生成,用虛擬人做短視頻。而Sora是視頻生成類大模型,通過輸入文本或圖片可生成、連接、擴展等多種方式編輯視頻,屬於多模態大模型范疇,該類模型是在GPT這類語言類大模型上進壹步延伸、拓展。Sora通過壹種類似於GPT-4對文本令牌進行操作的方式來處理視頻“補丁”。該模型的關鍵創新在於將視頻幀視為補丁序列,類似於語言模型中的單詞令牌,使其能夠有效地管理各種視頻。這種方法與文本條件生成相結合,使Sora能夠根據文本提示生成上下文相關且視覺上連貫的視頻。
具體原理上,Sora主要通過叁個步驟實現視頻訓練。首先是視頻壓縮網絡,將視頻或圖片降維成壹個緊湊、高效的形式。其次是時空補丁提取,將視圖信息分解成壹個個更小的單元,每個單元都含有視圖中壹部分的空間和時間信息,便於Sora在之後的步驟中能進行針對性處理。最後是視頻生成,輸入文本或圖片進行解碼加碼,由Transformer模型(即ChatGPT基礎轉換器)決定如何將這些單元轉換或組合,從而將文本和圖片提示中的內容形成完整的視頻。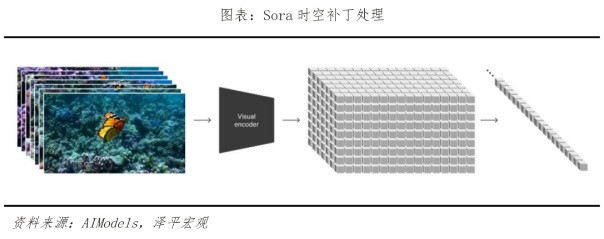
Sora在視頻生成模型最關鍵的兩項指標——時長和分辨率上大幅超越先前模型,並且具備較強的文本理解深度和細節生成能力,可以說是AI界的又壹裡程碑級的產品。Sora發布前,主要模型如Pika1.0、Emu Video、Gen-2可生成時長分別為3~7秒、4秒、4~16秒;而Sora可生成時長高達60秒,能實現1080p分辨率,且Sora不僅能基於文本提示生成視頻,也具備視頻編輯和擴展能力。Sora對文本的深度理解也較強。在大量文本解析的訓練下,Sora可以准確捕捉、理解文本指令背後的情感用意,並流暢、自然地將文本提示轉變為細節豐富、場景匹配的視頻內容。
Sora在視頻生成中可以較好地模擬壹個虛擬世界的物理規律,更好的理解物理世界,從而產生真實的鏡頭感。其技術特點主要有贰:- 新聞來源於其它媒體,內容不代表本站立場!
-
原文鏈接
原文鏈接:
目前還沒有人發表評論, 大家都在期待您的高見